STaR: Bootstrapping Reasoning With Reasoning
阅读这篇博文之前,请确保你对Cot有一定的了解:
研究背景主要是关于语言模型在复杂推理任务上的性能提升。文章指出,生成逐步“思维链”推理的理由可以提高语言模型在数学或常识问答等复杂推理任务上的性能。然而,目前诱导语言模型生成理由的方法,要么需要构建大规模的理由数据集,要么通过使用少量的推理进行推断来牺牲准确性。为了解决这个问题,文章提出了一种技术,即“自学习推理器”(STaR),通过迭代地利用少量的理由示例和没有理由的大型数据集,来逐步提升进行更复杂推理的能力。STaR的基本循环是:在给定少量理由示例的情况下,生成理由来回答多个问题;如果生成的答案是错误的,则尝试生成给定正确答案的理由;对最终产生正确答案的所有理由进行微调;重复上述步骤。实验证明,与直接预测最终答案的模型相比,STaR在多个数据集上显著提高了性能,并且在CommensenseQA上与一个30倍更大的最先进语言模型的微调性能相当。因此,STaR通过从自己生成的推理中学习,让模型自我提升。
具体而言,STaR方法首先使用少量的rationale示例来提示模型生成rationale,并根据生成的答案进行反馈。如果生成的答案是错误的,那么就再次尝试生成rationale,给出正确答案的情况下更容易生成有用的rationale。然后,将所有最终得到正确答案的rationale进行微调。通过这种方式,STaR方法能够让模型通过学习自己生成的推理过程来不断改进自身的性能。
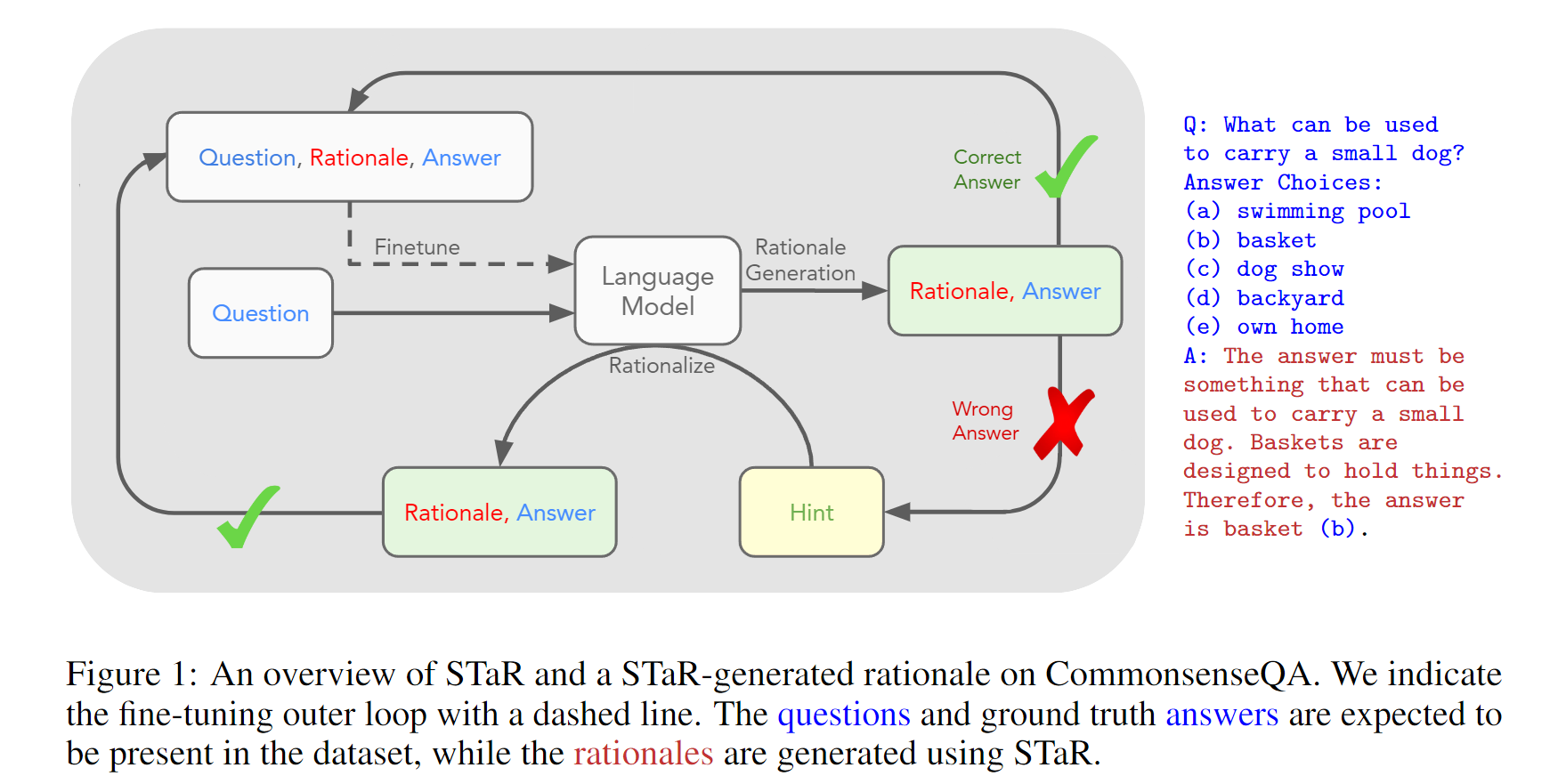
在STaR方法中,当模型无法正确回答问题时,提供正确答案来生成新的解释可以改善模型的性能的原因是,通过提供正确答案,模型可以学习到正确的推理过程和解释方式。模型可以通过生成解释来回答问题,如果生成的答案是错误的,模型可以再次尝试生成解释,直到生成的答案是正确的为止。通过这种迭代的方式,模型可以逐渐提升其推理能力。在每次迭代中,模型会使用所有最终生成正确答案的解释进行微调,从而进一步改善性能。因此,通过提供正确答案来生成新的解释可以帮助模型学习到正确的推理方式,从而提高性能。