Dense Reward for Free in Reinforcement Learning from Human Feedback

关键词:稠密奖励、RLHF
RLHF用的一般是稀疏奖励,这里不再赘述,本论文想解决的问题就是如何将奖励稠密化的问题。
抛开奖励是否稠密的问题,Reward Model一般是一个llm backbone + MLP网络,对于一个sentence,Reward Model一般输出一个值的序列v,设最后一个有效token的index为k,那么整个句子的score即为v[k],随后按照BT范式进行训练即可。
ok,那这篇论文将奖励稠密化的方式就是取llm backbone最后一层attention layer计算得到的权重矩阵,并以此为信度分配的标准获得句子上每一个token的reward。如果读到这里,你对实现细节比较疑惑,请跳转到下面的代码实验部分。
最优策略的保持
代码实验部分
def forward(
self,
input_ids=None,
past_key_values=None,
attention_mask=None,
position_ids=None,
):
"""
input_ids, attention_mask: torch.Size([bs, seq_len])
return: scores: List[bs]
"""
bs = input_ids.shape[0]
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
position_ids=position_ids,
)
hidden_states = transformer_outputs[0]
scores = []
rewards = self.v_head(hidden_states).squeeze(-1)
for i in range(bs):
c_inds = (input_ids[i] == self.PAD_ID).nonzero()
c_ind = c_inds[0].item() if len(c_inds) > 0 else input_ids.shape[1]
scores.append(rewards[i, c_ind - 1])
return scores, transformer_outputs.attentions
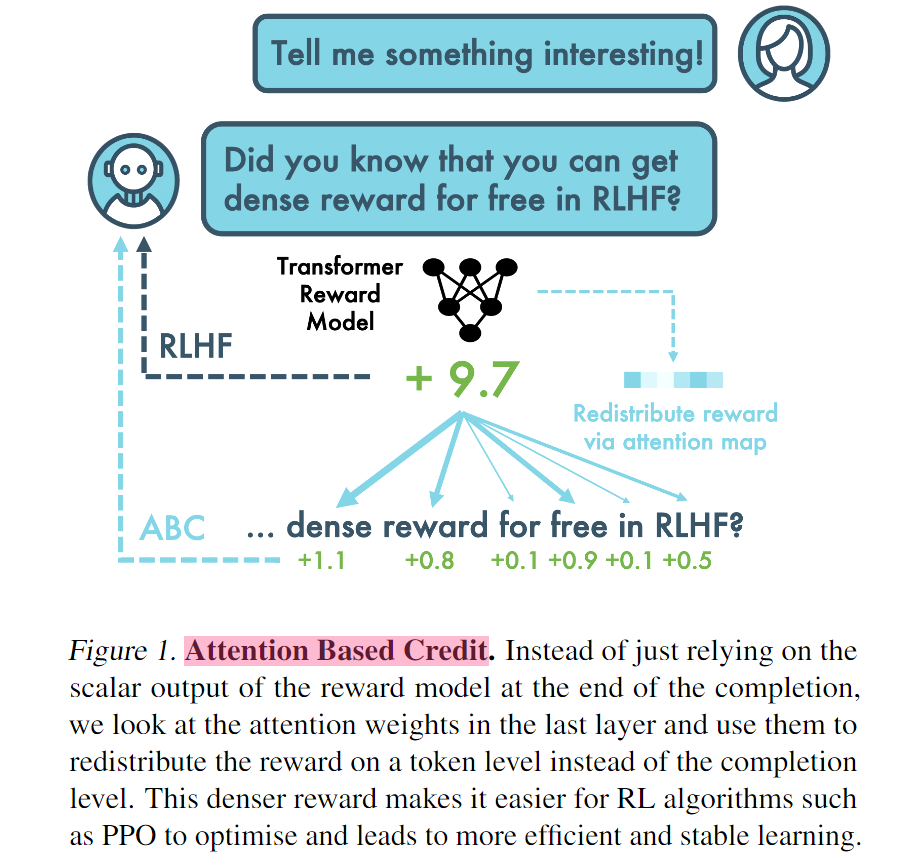
这么看起来,整个建模方式确实很简洁。
ok,接下来我们来看看实验部分。
IMDB Dataset
目标: Positive Generation,引导GPT2生成正面评价。这里需要参考我之前写过的IMDB数据集的介绍,注意到rward model的训练并不是基于BT的。
Building on a GPT2 model that has already been trained on a single epoch of the IMDb dataset for unsupervised next-token prediction as a starting point, this is used to create two models; the first is fine-tuned further on the labelled dataset to predict the classification of a given review. We take the logit(pos) - logit(neg) of this model as the reward signal to train the second model.
实验结果:
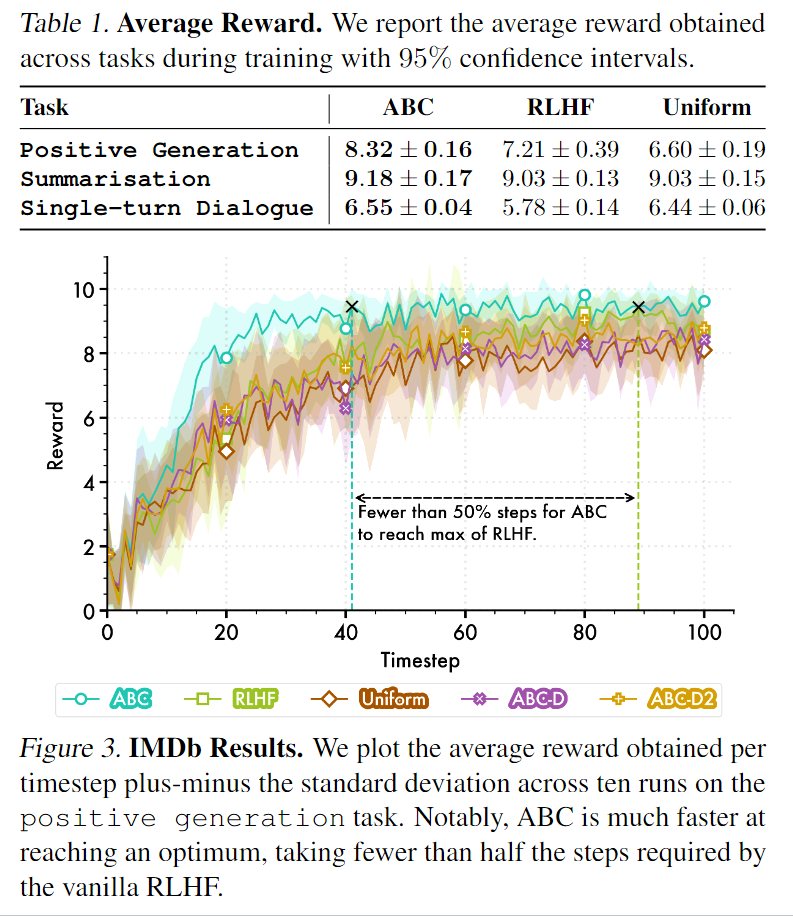
这里需要对对比的算法进行一些说明:
- ABC - Proposed method, using the attention map of the generator policy model to assign rewards to each token in the completion.
- RLHF - Vanilla RLHF optimising the sparse reward obtained at the end of a completion.
- Uniform - We take the episodic reward and smooth it over the length of the completion.
- ABC-D - An ablation of ABC where we use the attention map of the generator policy model instead of the reward model; full details in Appendix B. ABC-D uses a weighted average attention map over the course of the generation, while ABC-D2 takes the attention map while predicting the final token