UltraFeedback
该工作从6个公开的高质量数据集中抽取了63,967条指令。
图1显示了ULTRAFEEDBACK的构建过程,从大型数据池中抽取指令和模型样本,以保证对比数据的多样性,然后通过详细图解查询GPT-4,以获得文本和数字格式的精细和高质量标注信息。
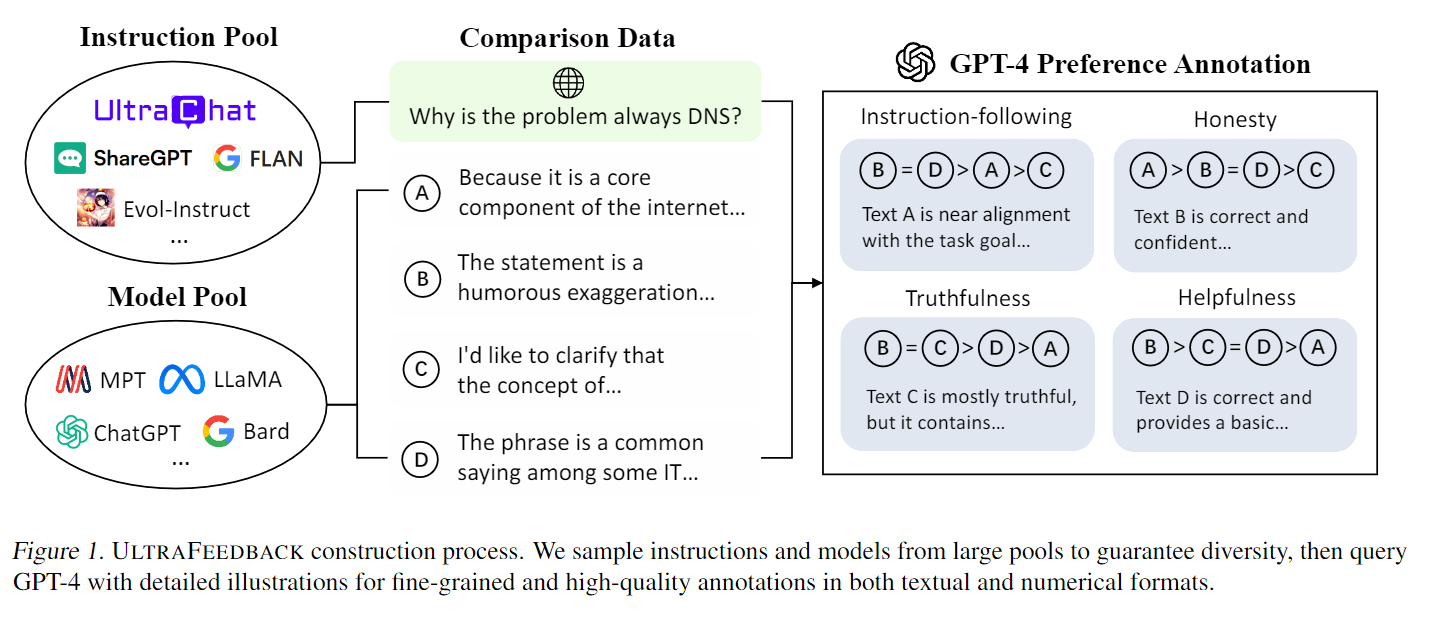
数据集构建
指令采样和指令标注两个阶段:
指令采样
为了获得不同程度的完成度,该工作调查了评估LLMs某些能力的数据集。包括TruthfulQA和FalseQA中的所有指令,分别从Evol-Instruct和UltraChat中随机抽样10k条指令,并从ShareGPT中抽样20k条指令。
对于FLAN,采用了分层抽样策略,从"CoT"子集中随机抽取3k条指令,在其他三个子集中每个任务抽取10条指令,同时排除那些过长的指令。
进行数据污染检测,过滤掉与AlpacaEval、UltraChat测试集和EvolInstruct测试集重叠的数据。
最后,从六个公开的高质量数据集中抽取了63967条指令。
指令标注
根据63967条指令生成255864个模型完成项后,使用GPT-4为每个完成项提供两种类型的反馈:
(1)标量分数,表示多个方面的细粒度质量;
(2)文本批注,提供如何改进完成项的详细指导。
为避免主观标注,提供每个方面的详细文档供GPT-4参考。在每份文档中,会简要介绍每个方面的定义,然后详细说明从分数1到5的预期行为
数据集应用
奖励模型:UltraRM
- HuggingFace 地址:🔗 https://huggingface.co/openbmb/UltraRM-13b
就像老师为不同学生的答案给出评分,分数高低其实就是收到的奖励大小。高分答案可以指引大家后续的回答方向。同理,UltraRM 是大模型后续进行RLHF的基础,也是衡量反馈数据集质量的重要维度。
UltraRM 由 LLaMA2-13B 初始化,在 UltraFeedback 和三个开源数据集(Anthropic HH-RLHF, Stanford SHP和OpenAI Summarization)组成的混合数据集上进行微调。在四个公共偏好测试集上,UltraRM 显著超过其他开源奖励模型,达到了 SOTA 的性能。