DDPM:

推荐阅读1 推荐阅读2 数学推导 生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
Diffusion model也就是ddpm原论文其实并不是太好理解,原因是作者在推导过程当中省略了非常对于初学者来说必要的步骤,毕竟它是作为一篇论文,受限于篇幅的原因,里面的公式肯定没办法写得非常详细。
下面这个Tutorials写的非常不错,个人觉得里面的推导是比较符合一个初学者认知的逻辑。

本文假设读者已经简单地了解过DDPM,并且已经阅读了论文或者上面的讲义,这里做一个简单的总结。
DDPM 理论推导
首先是DDPM的结构:
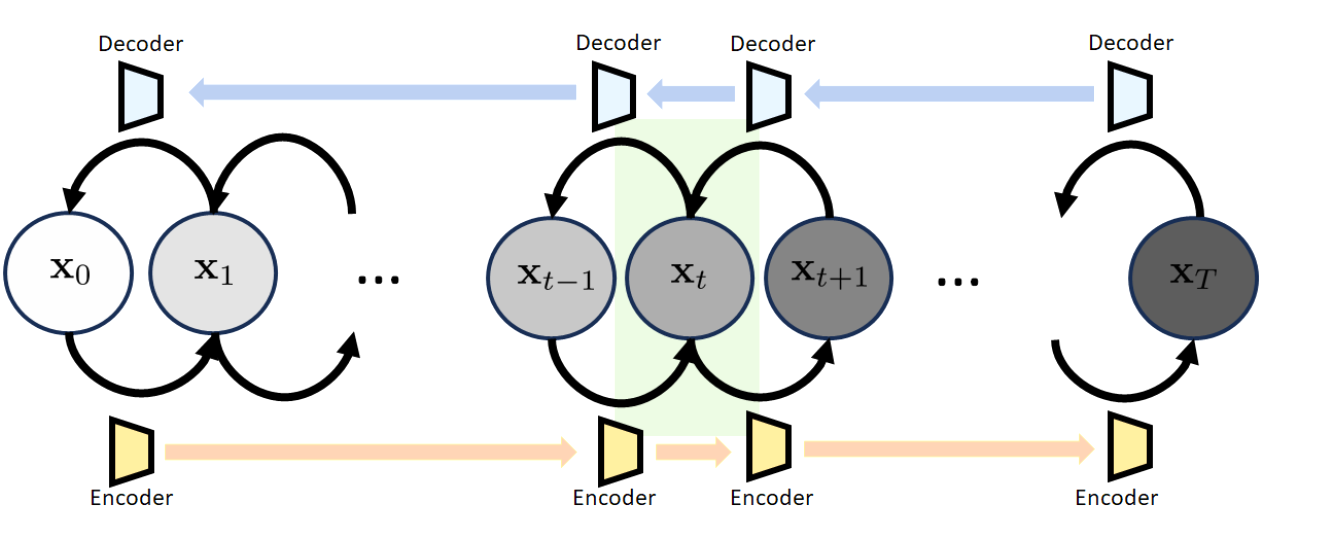
与VAE的不同之处是DDPM的latent variable与输入的x保持一样的大小。
每一个block对应一个前向分布和一个后向分布,如下图:
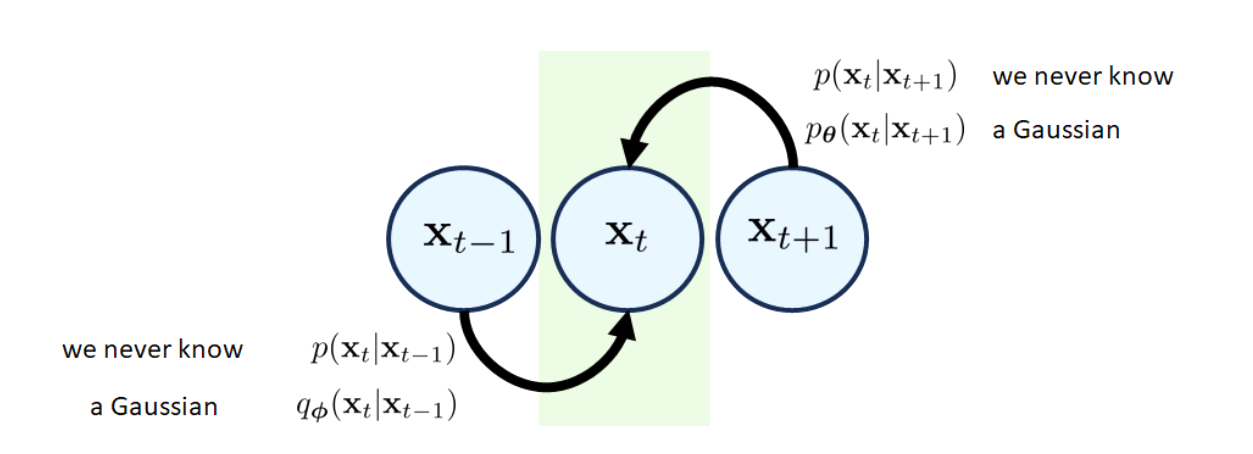
前向分布是一个人为设定好的不带可学习参数的分布,满足如下定义:
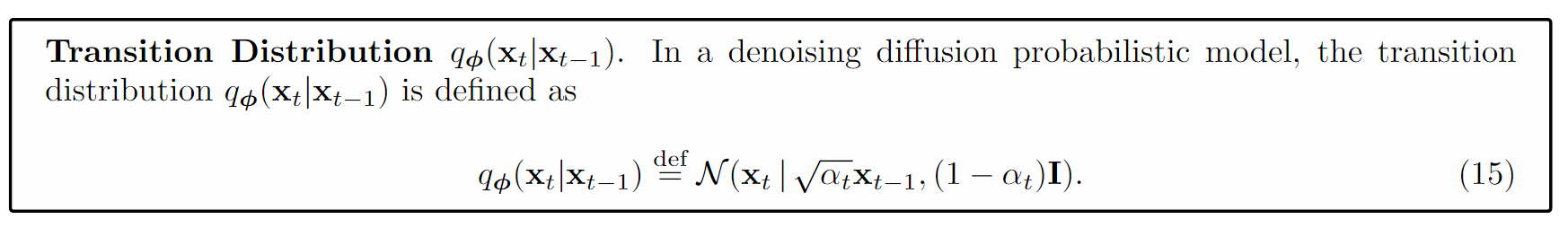
这里的是一个预先设定好的超参数,随着t的增大而减小,代表加入的噪声的比例越来越大,至于为什么要这么设定, 可以从直观角度和理论角度去分析:(直观角度)比如水中加糖,刚开始加糖的时候,水的味道变化不大,但是加的越多,水的味道就会变得越甜,为了使得水的糖度增加的更加均匀,我们可以逐渐增加加糖的量;(理论角度)这个超参数的设定是为了使得我们的分布逐渐变得更加接近高斯分布,其实上面的讲义做了一个比较详细的证明,可以去详细看看,这里就不再赘述。
我们在假设了前面这样一个分布之后呢,按照一定的推导的方式,其实我们就可以得出来是完全只跟我们的相关的。我们有以下结论:

其中。证明其实也不是特别困难,b站和知乎的一些推文都有详细的推导,核心是高斯分布自带的一些性质,此处不再赘述。
ELBO
直接放结论:

对比一下VAE,假如我们的,那么前面这个ELBO就会退化成VAE的ELBO的形式。
证明请参考前面的讲义。
我们重点关注一致项,里面出现了和两个分布,我们在前面已经知道了、、的分布有给定形式,那么一致项里面的是不是也有闭式解呢?答案是肯定的。

既然我们已经知道了一致项里面的是高斯分布,而优化目标又是KL,那我们何不假设也是一个高斯分布呢?
即:
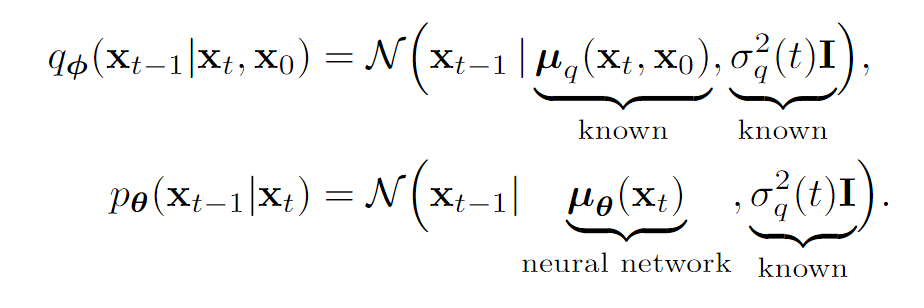
因此:
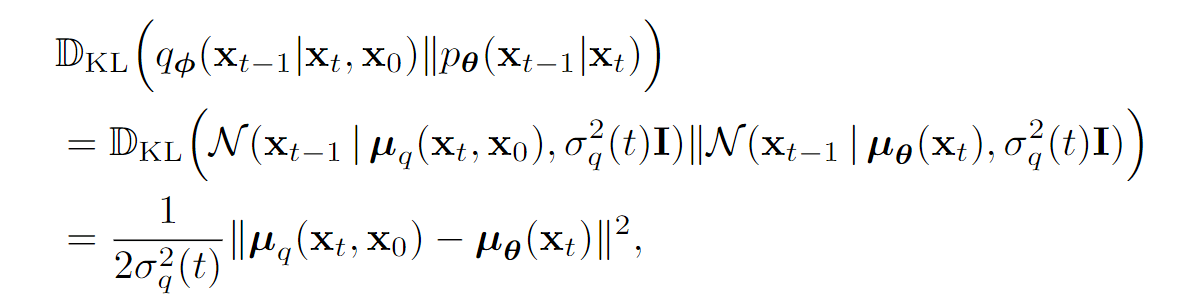
两个高斯分布之间的KL散度是有闭式解的: TBD
直接用前面的KL定义进行训练是没有问题的。但是因为本身的形式就比较复杂,我们完全可以通过下面的方式简化的设计:
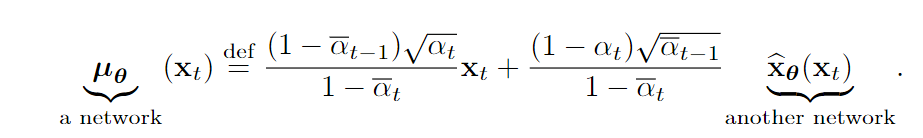
带入得到:
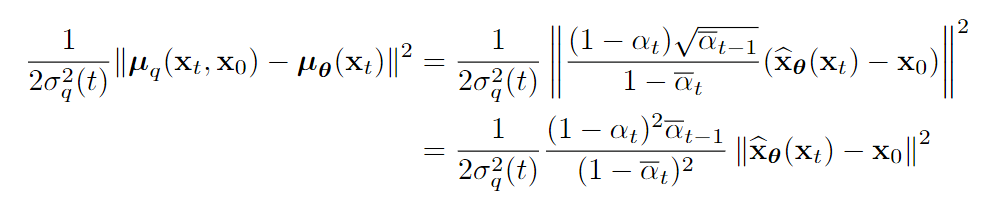
再带入ELBO的定义,我们得到了第一个版本的损失:

这个损失比较有意思,完全基于进行重建预测:

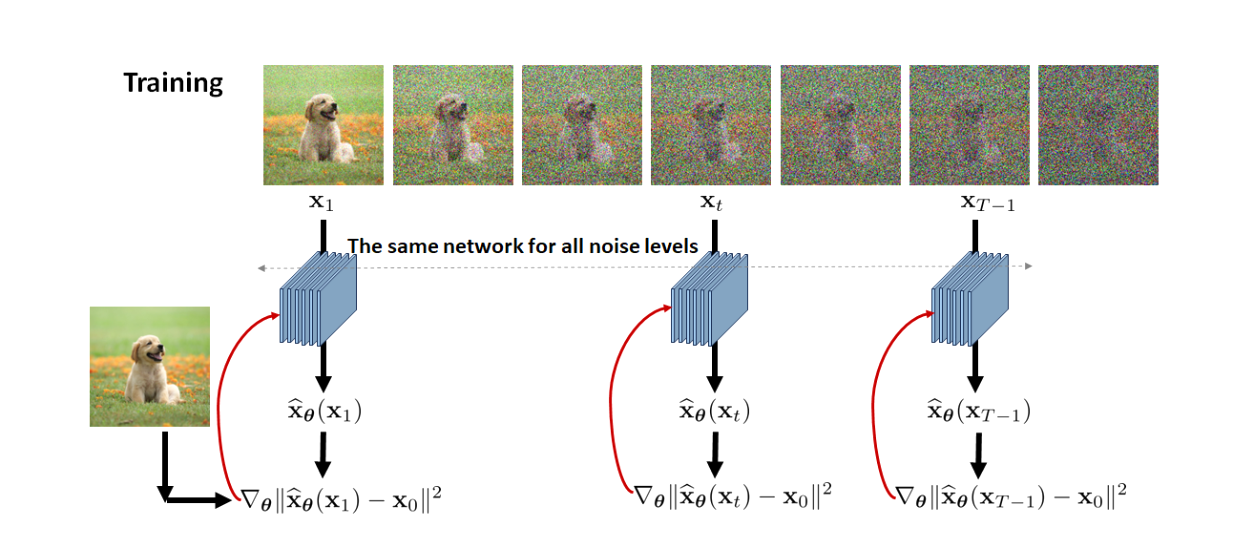
局部总结
如何理解DDPM呢?这里给出我的个人建议:
- 黑箱认知:输入、输出分别是什么?任务是什么? 回答:输入一个高斯噪声图片,输出一个真实图片。任务是生成图片。
- 把黑箱子一步步拆开,需要先了解VAE,由此我们知道DDPM里面有两个分布,一个是前向分布,一个是后向分布。其中分布是不带参数的预先设定的分布,分布是带参数的分布,需要学习。
- 推导ELBO,这里的ELBO和VAE的ELBO是非常相似的,只不过多了一个时间维度,这里的时间维度是指的个时间片。
- 具体工程上,因为对的实例化方式有两种,因此实现有两种方式
- 基于重构的版本
- 基于预测的版本。
Unet
DDPM讲到这里,似乎都是一些理论上的推导,我们并没有看到一个实际的网络结构。那么我们如何将DDPM应用到实际的图像生成任务中呢?这里我们就要引入Unet了。
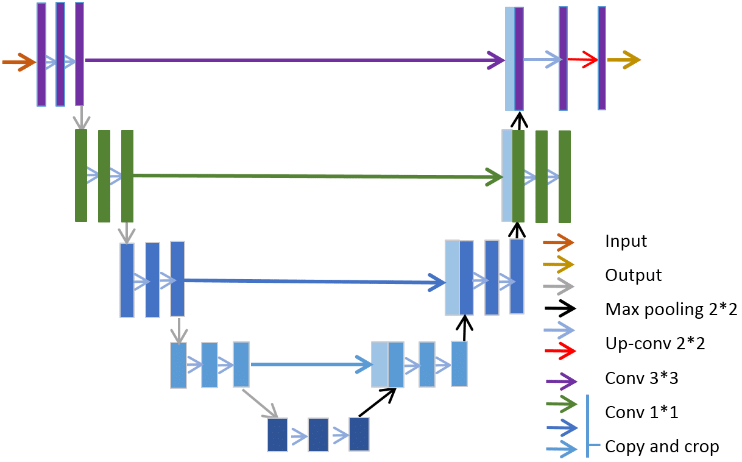
个人理解在相加的方式下,feature map 的维度没有变化,但每个维度都包含了更多特征,对于普通的分类任务这种不需要从 feature map 复原到原始分辨率的任务来说,这是一个高效的选择;而拼接则保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势。
Unet的一个最突出的contribution便是它的skip connection操作,很好地解决了由于下采样操作所丢失掉的细节损失(比如边界信息,这对于语义分割这种dense 预测型任务来说是至关重要的),从而帮助网络更好的完成精确的定位。相对于add操作,concat操作虽然增加了计算量,但是却能保留更多的空间信息,然后利用卷积层去进行一个特征的提取,通过这种利用学习的方式来融合adjcent-level feature显然会比直接将两者add来的更加有效。同样地道理,上采样一般采用反卷积会比直接双线性插值来的效果要好,当然如果模型处于过拟合的状态下应用反卷积就会起得适得其反的作用。Unet的分割精度很大程度上也取决于Backbone的选择,剩下的就是选择一些合适的数据增强和以及合理的后处理方式。
(TBD)条件扩散模型:Classifier-Guidance

早期的DDPM和DDIM是扩散模型的开创性算法,但是它们并没有将条件信息引入到生成过程中,因此它们生成的内容虽然真实,但确是随机的。当时如果我们希望扩散模型生成指定类型的图像,我们一般是在指定类型的数据集上训练这个扩散模型。我们这里介绍在条件扩散模型(Conditional Diffusion Model)方向具有重要意义的一个算法,也是提出了Classifier Guidance思想的文章《Diffusion Models Beat GANs on Image Synthesis》。
Classifier Guidance的思想并不复杂,DDPM可以看做由一个通过对随机噪声进行个时间片的去噪,最终得到目标图片的过程,每个时间片都是从前一个时间片预测当前时间片,表示为,其中是扩散模型的参数。那么Classifier Guidance相当于通过前一个时间片的内容和类别标签共同得到生成图像的过程,表示为。这样我们就可以通过给定类别标签来生成指定类别的图像。Classifier Guidance使用起来很简单,但是论文涉及的推导过程又非常复杂,这里尽量用一种简单但易于理解的方式来讲明白这个推导过程。