Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations

verifier分为ORM(outcome reward model)和PRM(process reward model)两类,虽然PRM效果优于ORM,但是缺点很明显,需要人工标注训练集,即标注solution(CoT)中每个step正确与否的标签。Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations是清华&&DeepSeek等单位发表在ACL 2024的一项工作,本文提出了一种自动创建PRM训练集的方法,因为都是在数学数据集上训练和验证,作者将训练好的verifier称为math-shepherd。
要训练PRM,肯定需要为solution中每个step创建一个分数label,既然不想要人工标注(0,1),那么是否有其他方法为step创建出一个分数呢?这个分数的物理含义又是什么呢?作者是将step分数定义为从当前step出发,继续完善solution能得到正确答案的可能性。
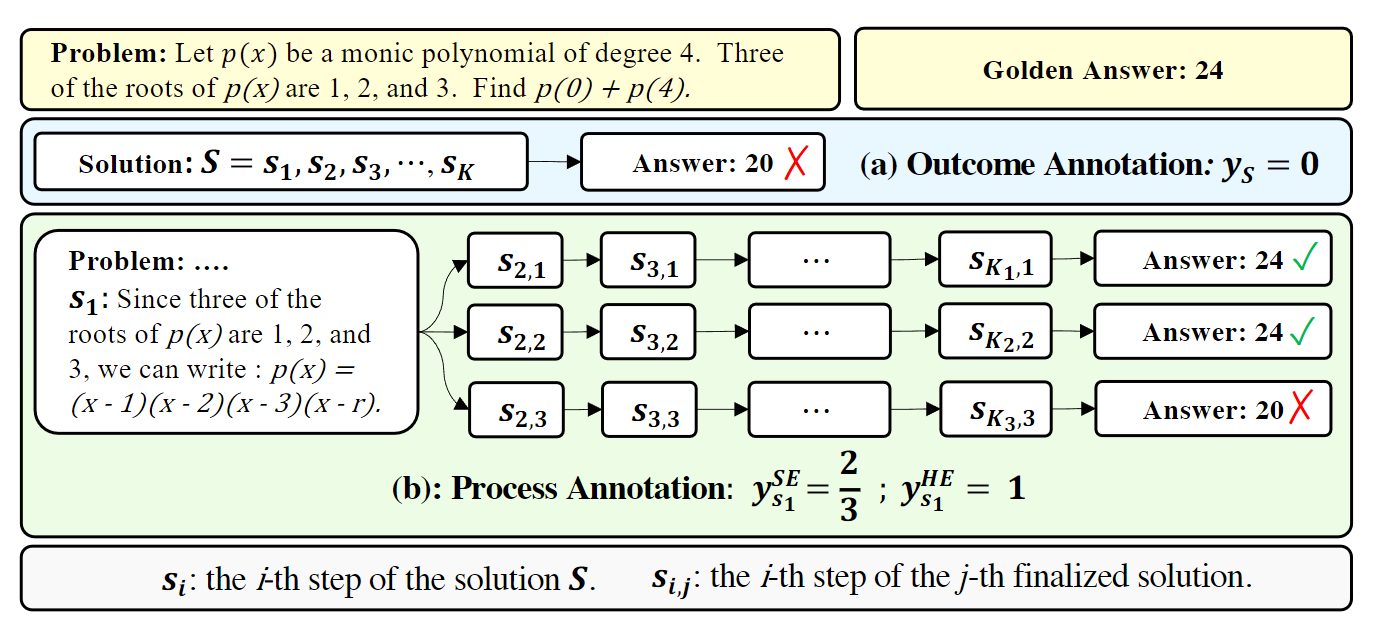
从step i 出发,利用LLM得到直到推导出answer a,论文中把这个LLM称为completer,然后和问题的答案a*对比,我们可以从i采样多条solution,如果大部分answer都正确,我们就认为step i 很重要,具有高分数。
有了数据集接下来就是训练PRM。
为了验证PRM有效性,作者采用了两种实验方案:
- 对于测试集的每条数据,generator生成多个候选solution,verifier来打分输出top1,看看正确答案的占比,这也是验证verifier有效性的标注实验。其实就是BoN
- 既然verifier也是reward model,作者结合step-by-step PPO和verifier来提升LLM,然后对于测试集的数据,用RL提升后的LLM做贪心解码只生成一条solution,计算正确答案的占比