SRPO: Score Regularized Policy Optimization through Diffusion Behavior

关键词:
- Offline RL
- Diffusion Model
想要解决什么问题?
Diffusion RL的文章,尽管Diffusion Model的表达能力很强,能够很好地刻画复杂的分布,但是采样效率很慢。因此,本文想要解决的就是Diffusion Model采样效率慢的问题。这篇跟QGPO一样,是朱军老师团队的文章,SRPO里面的baseline比较了QGPO,从效果上看,QGPO效果更好,但是效率上看远远不如SRPO,所以综合看来,这篇文章还是很不错的。
具体来说,我们希望通过跳过采样action的过程,直接进行学习,至于怎么学,请看下文分解。我们先来看一下最后的采样效率和效果的对比图:
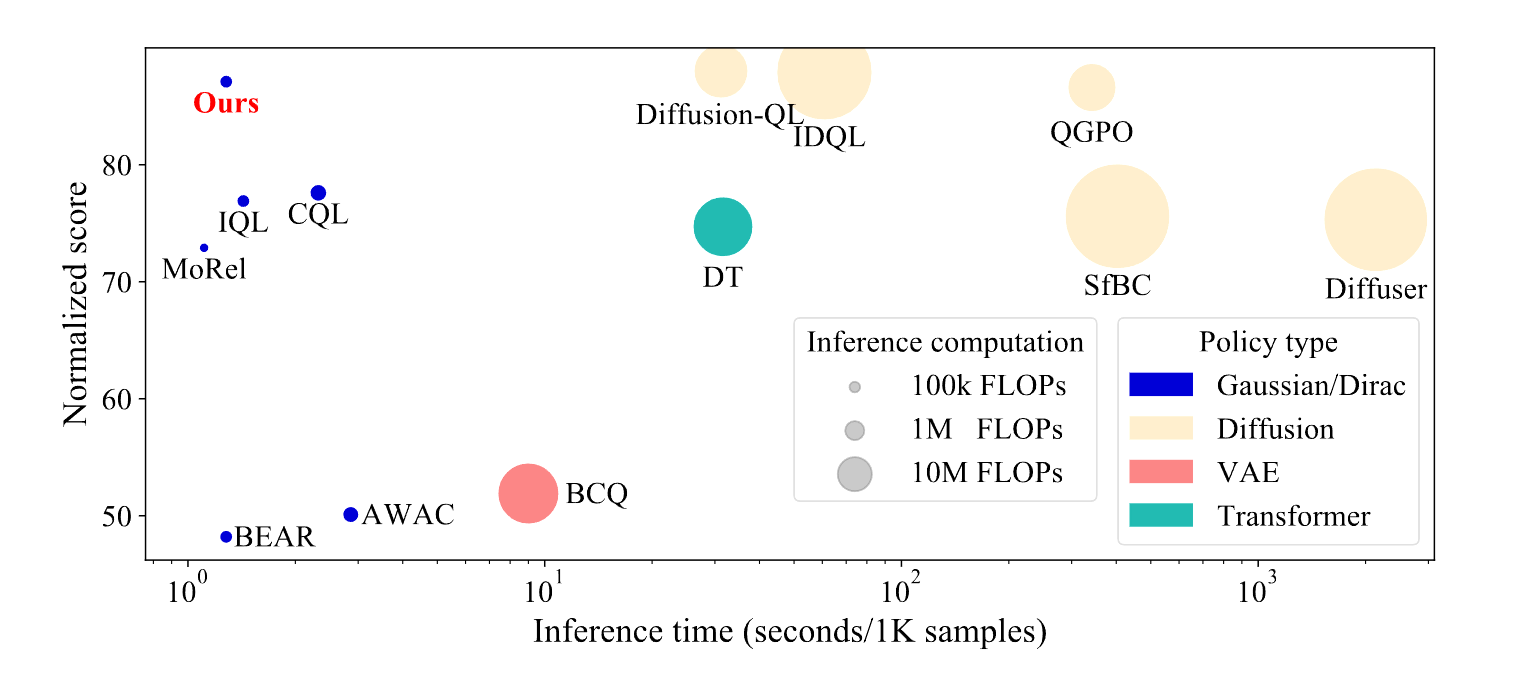
从图中可见,SRPO的效率和效果都非常不错。而很多Diffusion-Based的算法尽管效果比IQL、CQL等经典算法好,但是action采样的效率很低,尤其是Diffuser,轨迹性的建模更是对其采样效率带来了灾难性的影响。