BasicKnowledge:一些工程上的学习笔记
模型中常见的数值类型
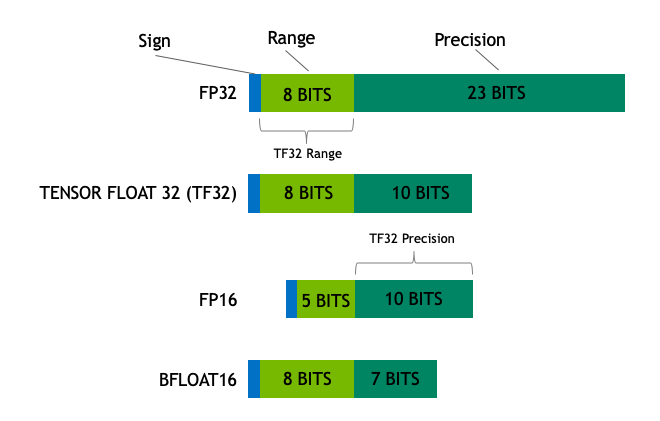
- Float32 (FP32) 。标准的 IEEE 32 位浮点表示,指数 8 位,尾数 23 位,符号 1 位,可以表示大范围的浮点数。大部分硬件都支持 FP32 运算指令。
计算公式:
其中: sign 是符号位,0 表示正数,1 表示负数。 exponent 是指数部分,使用偏移量编码,偏移量为 127。 fraction 是尾数部分,表示在 1 之后的小数部分。
- Float16 (FP16) 。指数 5 位,尾数 10 位,符号 1 位。FP16 数字的数值范围远低于 FP32,存在上溢 (当用于表示非常大的数时) 和下溢 (当用于表示非常小的数时) 的风险,通过缩放损失 (loss scaling) 来缓解这个问题。
计算公式:
其中: sign 是符号位,0 表示正数,1 表示负数。 exponent 是指数部分,使用偏移量编码,偏移量为 15。 fraction 是尾数部分,表示在 1 之后的小数部分。当expoent全1时,小数部分为0时,表示无穷(取决于符号位是正无穷还是负无穷);当expoent全1时,小数部分不为0时,表示NaN。
- Bfloat16 (BF16) 。指数 8 位 (与 FP32 相同),尾数 7 位,符号 1 位。这意味着 BF16 可以保留与 FP32 相同的动态范围。但是相对于 FP16,损失了 3 位精度。因此,在使用 BF16 精度时,大数值绝对没有问题,但是精度会比 FP16 差。
- TensorFloat-32(TF32) 。使用 19 位表示,结合了 BF16 的范围和 FP16 的精度,是计算数据类型而不是存储数据类型。目前使用范围较小。
torch.int8()
model.generate()详细解析
核心代码来自:
# _sample()方法
while self._has_unfinished_sequences(
this_peer_finished, synced_gpus, device=input_ids.device, cur_len=cur_len, max_length=max_length
):
# prepare model inputs
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# prepare variable output controls (note: some models won't accept all output controls)
model_inputs.update({"output_attentions": output_attentions} if output_attentions else {})
model_inputs.update({"output_hidden_states": output_hidden_states} if output_hidden_states else {})
# forward pass to get next token
outputs = self(**model_inputs, return_dict=True)
if synced_gpus and this_peer_finished:
continue # don't waste resources running the code we don't need
# Clone is needed to avoid keeping a hanging ref to outputs.logits which may be very large for first iteration
# (the clone itself is always small)
next_token_logits = outputs.logits[:, -1, :].clone()
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
if do_sample:
next_token_scores = logits_warper(input_ids, next_token_scores)
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_token_scores,)
if output_logits:
raw_logits += (next_token_logits,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# token selection
if do_sample:
probs = nn.functional.softmax(next_token_scores, dim=-1)
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(next_token_scores, dim=-1) # greedy search
# finished sentences should have their next token be a padding token
if has_eos_stopping_criteria:
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
if streamer is not None:
streamer.put(next_tokens.cpu())
model_kwargs = self._update_model_kwargs_for_generation(
outputs,
model_kwargs,
is_encoder_decoder=self.config.is_encoder_decoder,
)
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
cur_len += 1
# This is needed to properly delete outputs.logits which may be very large for first iteration
# Otherwise a reference to outputs is kept which keeps the logits alive in the next iteration
del outputs
Greedy Search
Greedy search(贪婪搜索)是指在每个t时刻选择下一个词时,根据模型预测的概率分布直接选择概率最大的词。这种方法简单直接,但可能会导致生成的序列不够多样化。
代码逻辑:
def generate(self, input_ids, max_length):
for i in range(max_length):
logits = self.model(input_ids)
next_token = torch.argmax(logits, dim=-1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
return input_ids
Beam Search
Beam searchBeam search(集束搜索)对贪心搜索进行了改进,扩大了搜索空间,更容易得到全局最优解。Beam Search 包含一个参数 beam size k,表示每一时刻均保留得分最高的 k 个序列,然后下一时刻用这 k 个序列继续生成。从这里来看,该算法算是基于贪婪搜索的缺点来设计实现的。
缺点:还是会产生局部最优问题。在某些需要多样性的应用场景中,Beam Search可能会生成较为相似的答案,因为它倾向于选择评分最高的候选答案,这可能导致答案的多样性不足。
top-k Sampling
top-k采样Top-K采样限制在一定数量要考虑的tokens。在 Top-K 采样中,概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。
top-p Sampling
top-p采样Top-p采样限制在一定概率质量内的tokens。在 Top-p 采样中,会将概率质量大于给定阈值 p 的 tokens 保留下来,然后重新归一化这些 tokens 的概率,最后在这些重新被归一化概率后的 tokens 中采样。
总结:
Greedy Search 和 Beam Search 是确定性方法,它们在每个时间步选择最可能的词或序列,因此它们之间有一定的关联,Beam Search 可以看作是 Greedy Search 的扩展。
Top-k Sampling 和 Top-p Sampling 是随机性方法,它们引入了随机性来增加生成文本的多样性。这两种方法之间也有关联,因为它们都限制了采样的范围,但 Top-p Sampling 是基于概率质量的动态范围,而 Top-k Sampling 是基于固定数量的词。
拒绝采样

RFT(Rejection sampling Fine-Tuning)和SFT(Supervised Fine-Tuning)是两种用于微调机器学习模型的方法,特别是在自然语言处理领域。
SFT是一种常见的微调方法,主要步骤如下:
- 数据收集:收集大量的标注数据,这些数据通常由人类专家根据特定任务进行标注。
- 模型训练:使用这些标注数据对预训练模型进行微调,使其在特定任务上表现更好。
- 评估和优化:通过验证集评估模型性能,并根据结果进行优化。SFT的优点是相对简单直接,只需要高质量的标注数据即可。
然而,SFT也有一些局限性,比如对标注数据的质量和数量要求较高。RFT是一种更为复杂的微调方法,主要步骤如下:
- 数据生成:首先使用预训练模型生成大量的候选输出。
- 筛选过程:通过某种筛选机制(如人工评审或自动评分系统)从这些候选输出中挑选出高质量的样本。
- 模型训练:使用筛选后的高质量样本对模型进行微调。RFT的关键在于筛选过程,这个过程可以显著提高数据的质量,从而提升模型的性能。筛选机制可以是人工的,也可以是基于某种自动化评分系统的。
区别
- 数据来源:
- SFT:依赖于预先标注好的高质量数据。
- RFT:通过生成大量候选输出,然后筛选出高质量样本。
- 数据质量控制:
- SFT:数据质量主要依赖于标注过程的质量控制。
- RFT:通过筛选机制来确保数据质量,即使初始生成的数据质量不高,也可以通过筛选提高。
RFT通过引入多样化的推理路径,有助于减少模型在训练数据上的过拟合,特别是在大型模型中。