IQ-Learn: Inverse soft-Q Learning for Imitation

NeurIPS 2021 spotlight paper: IQ-Learn: Inverse soft-Q Learning for Imitation
值得反复琢磨的paper!
在读本文之前,请确保你熟悉以下内容:
熟悉的意思是对于这些论文出现的公式,这些论文的关联你应该可以用自己的语言清晰地阐述。
Max Entropy Inverse Reinforcement Learning
在介绍IQ-Learn之前,我们先来回顾一下Max Entropy Inverse Reinforcement Learning。这个在GAIL论文中进行详细推导,我们这里仅仅只是简单回顾一下。
对于一个凸正则函数:ψ:RS×A→R¯,该函数作为正则化项,用于评估一个rewrad函数的复杂程度。我们可以定义一个Max Entropy Inverse Reinforcement Learning的目标函数如下:
πminrmaxL(π,r)=EρE[r(s,a)]−Eρπ[r(s,a)]−H(π)−ψ(r)
其中,ρE是专家策略的分布,ρπ是学习到的策略的分布,H(π)是策略的熵,ψ(r)是reward函数的复杂度。
怎么理解这个目标呢?
首先先看内层的目标:
rmaxL(π,r)=EρE[r(s,a)]−Eρπ[r(s,a)]−ψ(r)
其表示当ρπ或者说π固定时,我们希望专家策略在这个reward函数下的期望值要尽可能大于学习到的策略在这个reward函数下的期望值,而同时这个函数r不能过于复杂,因此加了一个正则化项ψ(r)。
外层的目标就不难理解了,当r固定时,我们希望学习到的策略的熵和期望表现要尽可能大,即最大化Eρπ[r(s,a)]+H(π)。
而GAIL则证明了,上面的目标可以写成以下形式:
πmindψ(ρE,ρπ)−H(π)
其中,dψ(ρE,ρπ)=ψ∗(ρE−ρπ),这里的ψ∗是ψ的Fenchel共轭函数。
共轭函数的定义为:
ψ∗(y)=xmax{yTx−ψ(x)}
讲到这里,如果读者对共轭函数不太熟悉,请查阅相关资料,这里不再展开。
教程
Inverse soft Bellman Operator
我们都知道,Soft Bellman Operator是SAC中的核心,其定义如下:
Qπ(s,a)=r(s,a)+γEs′∼p(s′∣s,a)[Vπ(s′)]
其中,Vπ(s)=Ea∼π(a∣s)[Qπ(s,a)−αlogπ(a∣s)]。
Imitation Learning的目标是学习一个reward函数,使得学习到的策略的行为尽可能接近专家策略的行为。因此,我们可以定义一个Inverse soft Bellman Operator:
r(s,a)=Qπ(s,a)−γEs′∼p(s′∣s,a)[Vπ(s′)]
也就是说,我们如果知道了Qπ和Vπ,我们就可以通过上面的公式学习到reward函数。我们把这样的算子称为Inverse soft Bellman Operator,记作Tπ:RS×A→RS×A。
后文的写法中,(TπQ)(s,a)表示Tπ作用在Q上的结果。
直觉告诉我们,Tπ是一个双射算子,即对于任意的Q,TπQ都是唯一的。因此,我们可以通过迭代的方式来学习到Tπ的不动点,即reward函数。严格的证明我们这里就不展开了。
有了这样的观察,我们是不是可以考虑将原来的Max Entropy Inverse Reinforcement Learning的目标函数改写成以下形式:
J(Q,π)=EρE[(TπQ)(s,a)]−Eρπ[(TπQ)(s,a)]−H(π)−ψ(TπQ)
ok,这个便是IQ-Learn的核心思想。我们希望学习到的Q和π使得TπQ尽可能接近专家策略的行为,同时TπQ不能过于复杂。
我们有如下事实:
QmaxπminJ(Q,π)=rmaxπminL(π,r)
根绝Soft Q-learning和SAC的推导,假设我们已经知道了Q,那么其实不管是使用soft Q-learning还是SAC,我们都可以很容易地得到π的闭式解!
πQ(a∣s)=∫exp(Q(s,a))daexp(Q(s,a)
因此,maxQminπJ(Q,π)=maxQJ(Q,πQ),这个优化问题就变成了一个单变量的优化问题。
Drawing on connections between RL and energy-based models, we propose learning a single model for the Q-value. The Q-value then implicitly defines both a reward and policy function. This turns a difficult min-max problem over policy and reward functions into a simpler minimization problem over a single function, the Q-value.
我们并不急着继续将IQ-learn的算法流程,读者可以暂时抛开IQ-learn的细节,我们来看看dψ(ρ,ρE)与f-divergence的联系。
dψ(ρ,ρE)与f-divergence的联系
后面的分析是一个从一般到特殊,从抽象到具体的过程,因为我们即将“实例化”正则化函数ψ。
首先,ψ(TπQ)特殊化为:
ψg(r)=EρE[g(r(s,a))]
其中g是一个R→R的凸函数。你可以将r看成一个向量,那么g将这个向量的每一个值映射到一个新的值,得到一个新的向量g(r),这个向量与专家策略的分布做内积,得到一个标量ρETg(r)。这个式子表示我们衡量所学习的reward的复杂程度,是在专家的“状态-行为”占用度量下的期望。至于为什么不用策略π的占用度量呢?因为π本身也未知且在迭代中变化,并不稳定,而专家策略的占用度量是固定的。
这里便是我们的第一个具体化的地方。函数g将reward函数映射到一个向量,而ρE本身也可以看成一个向量,两个向量的内积便是我们的正则化项,所以也可以写成ρETg(r)。在这个过程中,占用度量作为一个权重分配到reward函数上,最终用于评判我们的rewrad的复杂程度。
再具体一点,我们可以将g定义为:
g(x)={x−ϕ(x),ifx∈Dom(ϕ)∞,otherwise
这里ϕ为凹函数,且Dom为ϕ的有效定义域。读者可能对为什么突然抛出这样一个定义感到好奇,我们之后再做解释,现在读者只需要知道这样定义的g是一个凸函数即可。
理解g看起来很奇怪的定义需要引入f-divergence的概念:
Df(ρ∣∣ρE)=Eρf(ρEρ)
引入共轭函数f∗,我们可以得到:
Df(ρ∣∣ρE)=q:X→RmaxEρE[q(x)]−Eρ[f∗(q(x))]
将q=−r带入上式,我们可以得到:
Df(ρ∣∣ρE)=rmaxEρE[−f∗(−r)]−Eρ[r]
记f∗(−r)=ϕ(r),我们可以得到:
Df(ρ∣∣ρE)=rmaxEρE[ϕ(r)]−Eρ[r]=rmaxρETϕ(r)−ρTr
回顾以下我们的dψ(ρ,ρE)的定义:
dψ(ρ,ρE)=ψ∗(ρE−ρ)=rmax(ρE−ρ)Tr−ρETg(r)
让dψ(ρ,ρE)=Df(ρ∣∣ρE),我们可以得到:
rmax(ρE−ρ)Tr−ρETg(r)=rmaxρETϕ(r)−ρTr
推出:
g(r)=r−ϕ(r)
在这个过程中,我们成功地将dψ(ρ,ρE)等价变形为f-divergence的形式,这样我们就可以用f-divergence来衡量ρ和ρE的差异,同时正则化了reward函数。(这句话一定要读懂,不然没办法理解为什么要这么定义g)。
这个将dψ(ρ,ρE)与f-divergence联系起来的过程是不可谓不精妙!
因此,dψ(ρ,ρE)的定义可以最终写成:
dψ(ρ,ρE)=ψ∗(ρE−ρ)=rmax(ρE−ρ)Tr−ψg(r)=rmaxρETr−ρTr−ρETg(r)=rmaxρETr−ρTr−ρET(r−ϕ(r))=rmaxρETϕ(r)−ρTr=rmaxEρE[ϕ(r(s,a))]−Eρr(s,a)
现在,我们选取不同的f-divergence,我们就可以得到不同的函数ϕ。如下表:
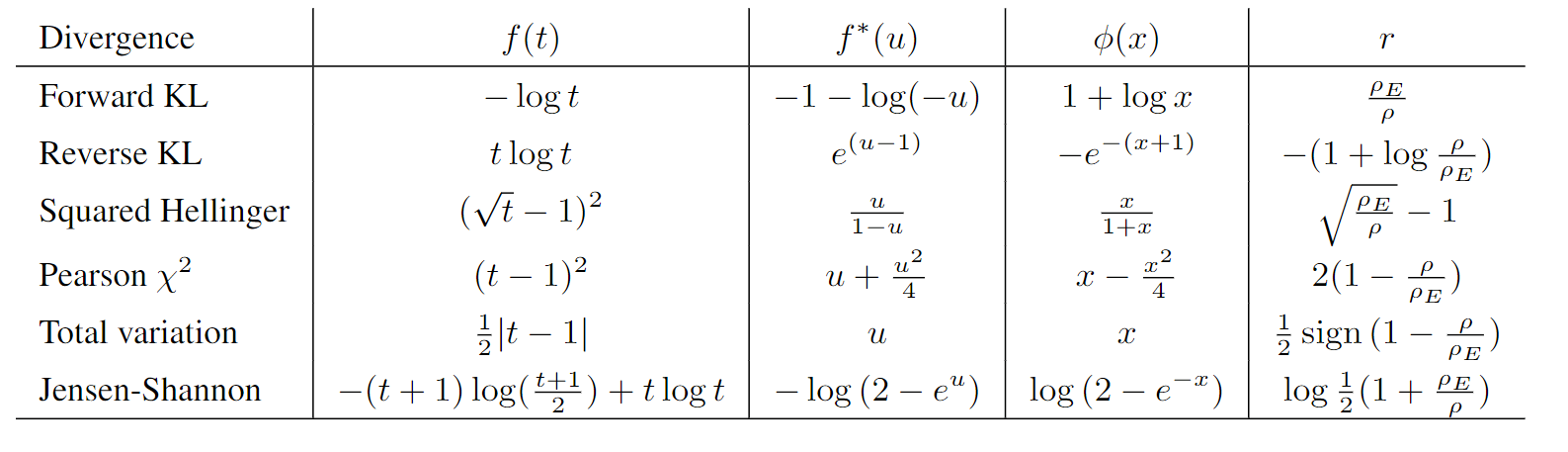
讲到这里,我们稍微回顾一下GAIL与本论文的理论上的关联,从本文视角下推导GAIL的目标函数:
将JS-divergence带入到maxrρETϕ(r)−ρTr得到:maxrρETlog(2−e−r)−ρTr,看起来跟GAIL的maxD∈(0,1)ρETlog(D(s,a))−ρTlog(1−D(s,a))形式上是很相似了,通过待定系数便可以确定到r与D的关系式了,因此该r用在GAIL的policy作为其reward是合理的。
IQ-Learn算法流程
我们现在可以回到IQ-Learn的算法流程了。
最开始的最大化目标:
J(Q,π)=EρE[(TπQ)(s,a)]−Eρπ[(TπQ)(s,a)]−H(π)−ψ(TπQ)
经过若干处理之后得到的式子(化简并不是很难,请自行查阅论文证明部分):
J(π,Q)=E(s,a)∼ρE[Q(s,a)−γEs′∼P(⋅∣s,a)Vπ(s′)]−(1−γ)Es0∼p0[Vπ(s0)]−ψ(TπQ)
考虑到ψ(TπQ)=EρE[g(TπQ)]=ρETg(TπQ),其中g(x)=x−ϕ(x),我们可以得到:
EρE[ϕ(Q(s,a)−γEs′∼P(⋅∣s,a)V∗(s′))]−(1−γ)Eρ0[V∗(s0)]
至于怎么使用Q计算V,不同的范式会采用不同的方法,具体参见Soft-Q Learning和SAC的推导。

论文中使用了两种实验setting,分别是Online和Offline,对应的计算(1−γ)Es0∼p0[Vπ(s0)]这一项的方法也有所不同。
- Online:使用E(s,a,s′)∼replay(expert and policy)[V(s)−γV(s′)]
- Offline: 使用E(s,a,s′)∼expert[V(s)−γV(s′)]
不用Vπ(s0)的原因是在实验中观测到过拟合的现象。
使用χ2-divergence,我们可以得到ϕ(x)=−f∗(−x)=x−4α1x2,即ψ(r)=4α1r2。
代码实现和简单实验验证
Offline IQ-Learn
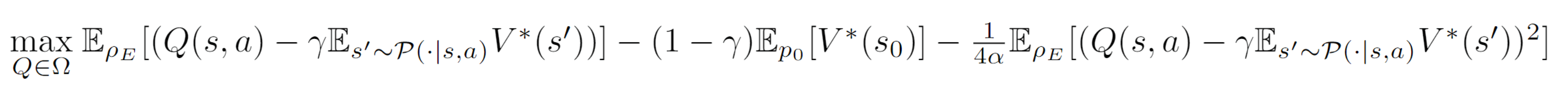
关键代码实现:
def offline_iq_loss(self, current_Q, current_v, next_v, batch):
obs, action, reward, next_obs, done, truncated, is_expert = batch
y = (1 - done) * self.gamma * next_v
reward = (current_Q - y)[is_expert == 1]
softq_loss = -reward.mean()
value_loss = (current_v - y)[is_expert == 1].mean()
regularizer_loss = 1 / (4 * self.method_alpha) * (reward**2).mean()
return softq_loss + value_loss + regularizer_loss
实验验证:
TBD
Online IQ-Learn
TBD
总结
IQ-Learn的思想就两点:
- 使用Q反过来表示reward函数
- dψ(ρ,ρE)与f-divergence的联系
这也是本文的行文思路。本文公式推导较多,请读者耐心阅读。
