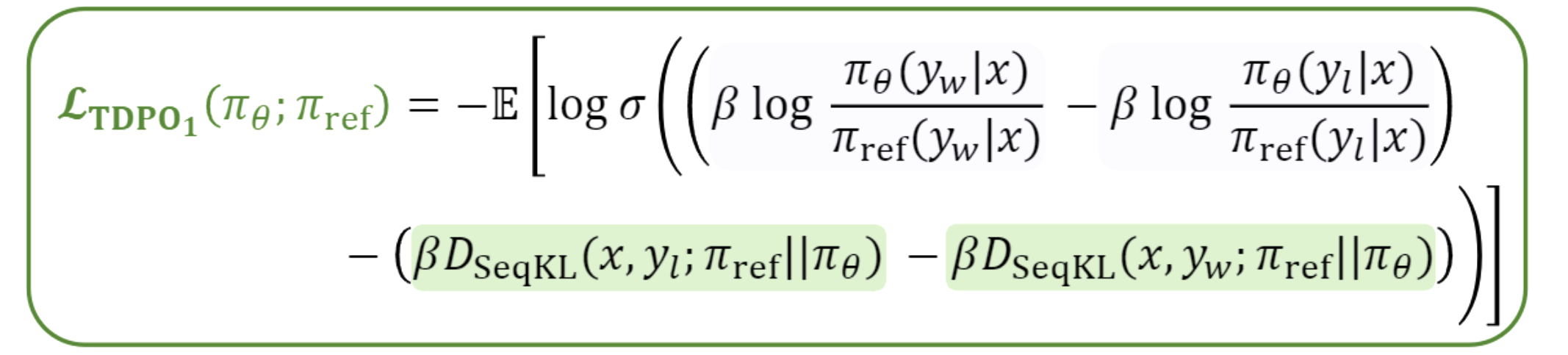TDPO
强化学习与LLM之间的符号关联说明
x代表prompt,y代表回答,二者均为序列。yt代表y的第t个token,y<t代表y的前t-1个token组成的序列。
定义状态st=[x,y<t],at=yt,rt:=r(st,at)=r([x,y<t],yt)
在LLM设定下,环境转移是完全确定的,给定当前的s和a,则s'为(s, a)的concat。
以下两种写法从一般到特殊:
RL:
Qπ(st,at)=Eπ[k=0∑γkrt+k∣st,at]
Vπ(st)=Eat∼π(∣st)[Qπ(st,at)]
Aπ(st,at)=Qπ(st,at)−V(st)
LLM:
Qπ([x,y<t],yt)=Eπ[k=0∑γkrt+k∣[x,y<t],yt]
Vπ([x,y<t])=Eyt∼π(∣[x,y<t])[Qπ([x,y<t],yt)]
Aπ([x,y<t],yt)=Qπ([x,y<t],yt)−V([x,y<t])
在本文设定下,γ=1。
逐步导出TDPO的目标
对于某一个状态s=[x,y<t],TDPO的优化目标为:
maxπθEz∼πθ(∣[x,y<t],z)[Aπref([x,y<t])],subject to: DKL(πθ∣∣πref)≤ϵ
这个形式其实并不少见,TRPO和AWR论文中均出现了非常类似的表述。这里做一个补充说明:
定义J(π)=Es0,a0,...[∑t=0∞γtr(st)]。
则策略π¯相比于旧策略π的期望收益为:
η(π¯)=J(π¯)−J(π)=s∑ρπ¯(s)a∑π¯(a∣s)Aπ(s,a)=Es,a∼π¯[Aπ(s,a)]
考虑到π¯和π不能离得太远,因此加上限制条件:
DKL(π¯∣∣π)=s∑a∑π¯(a∣s)logπ(a∣s)π¯(a∣s)≤ϵ
这样对比下来,TDPO的目标也就清楚多了。
用拉格朗日的方式转化以下TDPO的目标式子,得到:
θmaxE[x,y<t],z∼πθ([x,y<t])[Aπref([x,y<t],z)−βDKL(πθ([x,y<t])∣∣πref[x,y<t])]
这个期望为双重期望的形式,我们取出一层进行分析,我们将[x,y<t]简记为s, z即为a,固定s,我们需要最大化:
θmaxEa∼πθ(s)[Aπref(s,a)]−βDKL(πθ(s)∣∣πref(s))
我们先暂时抛开这个式子的求解,进入一个一般化的数学问题。
玻尔兹曼分布
还记得在soft q-learning中的一般化的数学问题吗?
待求解问题:
μmaxEx∼μ(x)[f(x)]+H(μ),s.t.x∑μ(x)=1
该式的最优解服从:
μ(x)=∑xef(x)ef(x)
回过头来看一下
θmaxEa∼πθ(s)[Aπref(s,a)]−βDKL(πθ(s)∣∣πref(s))=θmaxEa∼πθ(s)[Aπref(s,a)]−βa∑πθ(a∣s)logπref(a∣s)πθ(a∣s)=θmaxEa∼πθ(s)[Aπref(s,a)+βlogπref(a∣s)]+βH(πθ(s))
即最优解:
πθ∗(a∣s)=∑aeAπref(s,a)+βlogπref(a∣s)eAπref(s,a)+βlogπref(a∣s)=∑aπref(a∣s)eβ1Aπref(s,a)πref(a∣s)eβ1Aπref(s,a)=∑aπref(a∣s)eβ1Qπref(s,a)πref(a∣s)eβ1Qπref(s,a)=Z(s)πref(a∣s)eβ1Qπref(s,a)
其中最后一步的是因为A=Q−V而V只与s有关,在s固定的情况下,分子分母同时除以eβ1V(s),因此最优解其实是Q在πref(s)下的玻尔兹曼分布。
当πref(s)为均匀分布时,此时最优解的闭式解与Soft Q-learning的Max Entropy Q-learning的解完全一样,π∗∝exp(Q)。
类似与DPO,我们将Q进行反表示:
Qπref(s,a)=βlogπref(a∣s)π∗(a∣s)+βlogZ(s)
用advantage代替r -> BT-model目标等价性
本节推导目标:
∑t=1T1Aπ(swt,ywt)−∑t=1T2Aπ(slt,ylt)=∑t=1T1r(st,ywt)−∑t=1T2r(st,ylt)
截止到目前为止,TDPO的推导其实跟DPO的推导差不多,只不过TDPO因为降解到token-level,所以其最优化目标的期望为两层期望(s, a都需要求期望消除),但是DPO的期望只包含一层期望。但是其最优策略的推导本质上都是一个加权的玻尔兹曼分布。
将最优化的目标进行替换之后,TDPO的BT-model优化目标也随之变化:
PBT(y1>y2∣x)=σ(t=1∑T1γt−1Aπ([x,y1<t],y1t)−t=1∑T2γt−1Aπ([x,y2<t],y2t))
证明:
t=1∑T1Aπ(swt,ywt)−t=1∑T2Aπ(slt,ylt)=t=1∑T1(r(swt,ywt)+Vπ(swt+1)−Vπ(swt))−t=1∑T2(r(slt,ylt)+Vπ(slt+1)−Vπ(slt))=t=1∑T1r(swt,ywt)−t=1∑T2r(slt,ylt)+Vπ(swT1+1)−Vπ(slT2+1)−Vπ(sw1)+Vπ(sl1)
- EOS的影响,V(swT1+1)=V(slT2+1)
- 一开始y都是空的,即sw1=sl1=[x,y<1]=[x],V(sw1)=V(sl1)
因此:
∑t=1T1Aπ(swt,ywt)−∑t=1T2Aπ(slt,ylt)=∑t=1T1r(st,ywt)−∑t=1T2r(st,ylt)
于是BT-model的优化目标的改写是合理的。
最终损失推导
本节推导目标:
∑t=1TAπ(st,yt)=β∑t=1Tlogπref(yt∣st)π∗(yt∣st)+β∑t=1Tπref(yt∣st)logπ∗(yt∣st)πref(yt∣st)
证明:
Aπref(st,yt)=Qπref(st,yt)−Vπref(st)=βlogπref(yt∣st)π∗(yt∣st)+βlogZ(st)−Ey′∼πref(st)[βlogπref(y′∣st)π∗(y′∣st)+βlogZ(st)]=βlogπref(yt∣st)π∗(yt∣st)+βDKL(πref(st)∣∣π∗(st))
因此:
t=1∑TAπ(st,yt)=βt=1∑Tlogπref(yt∣st)π∗(yt∣st)+βt=1∑TDKL(πref(st)∣∣π∗(st))
因此