Generative Verifiers: Reward Modeling as Next-Token Prediction
概述
全新的reward model范式,看下面这个图就可以理解了:
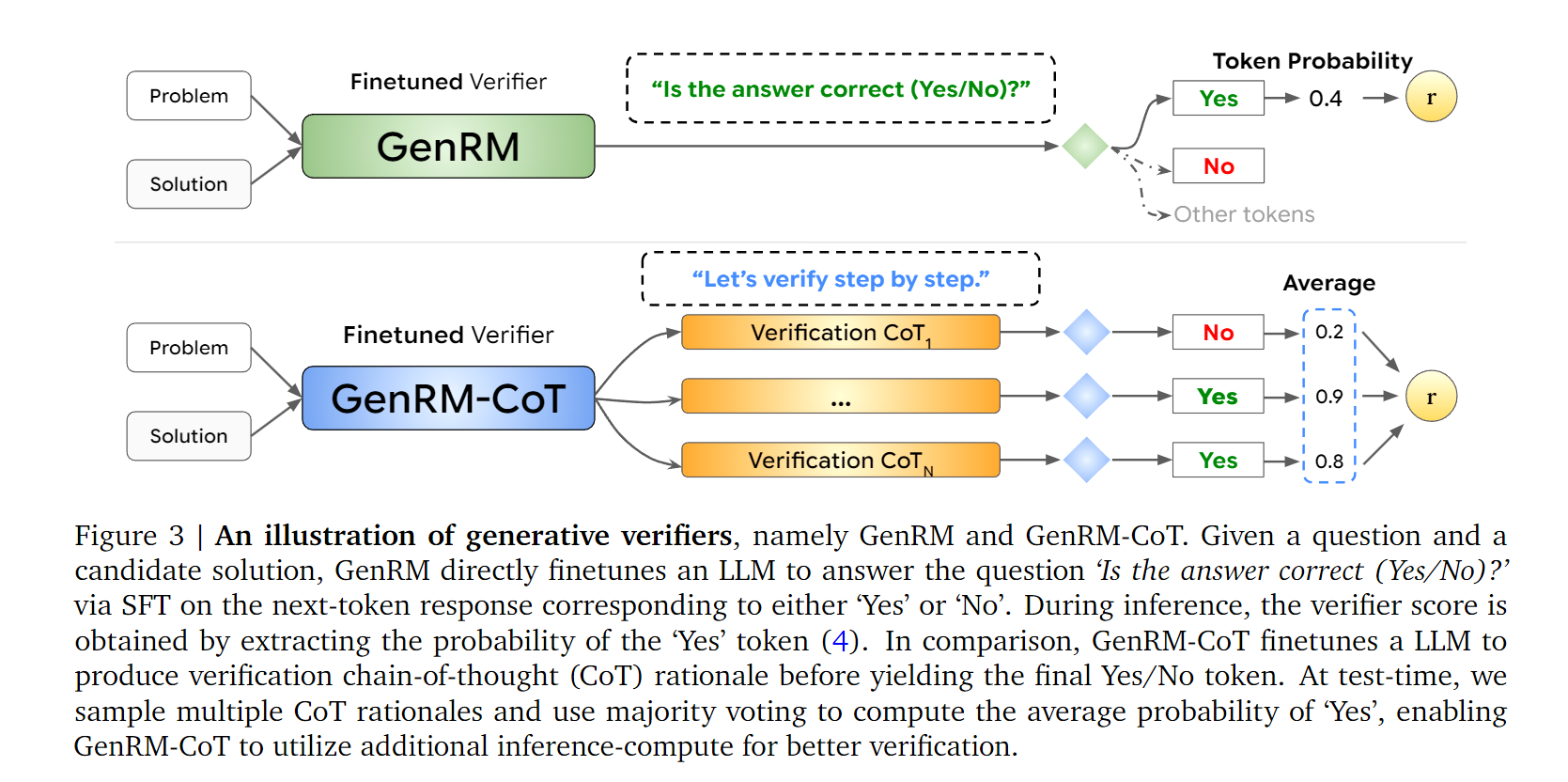
首先是抛弃了以往的lm backbone + linear head输出scalar reward的方式,原因是这种方式没能很好的利用lm强大的自回归能力。
简单来说,我们的reward的提取来自于[YES]这个token的输出的概率,概率越高,reward越大,概率越低,reward越小。OK,简单来讲将问题建模为Next-Token Prediction的问题。
算法
那我们下面就从简单到复杂讲解一下论文的算法。
Direct Verifier

一言以蔽之,我们通过SFT训练了一个verifier,输入(x, y, I),输出的[YES]的概率即为reward。那你可能会说我们传统阶段其实也有一个(x, y+)的SFT阶段,于是作者将两个loss进行融合:

这么做也没太多理论上的原因,实验上看起来确实在正确答案上训练更加有效:
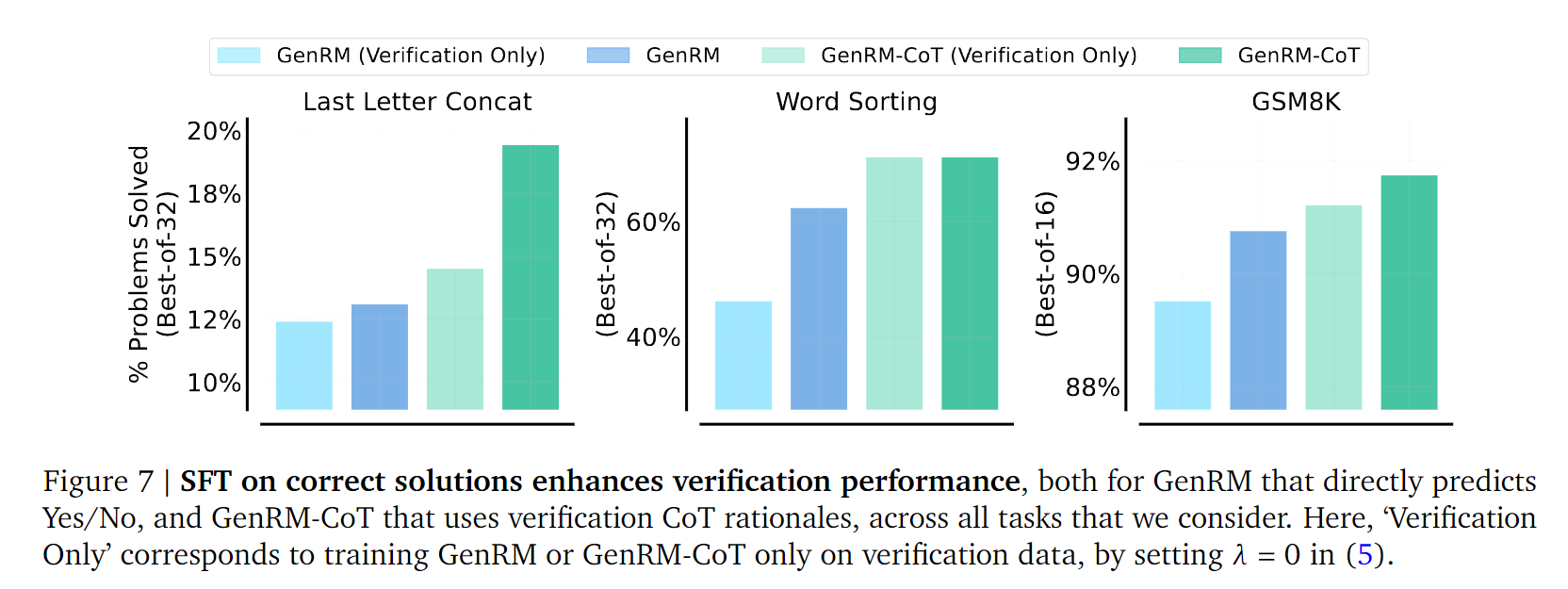
Take away: SFT on correct solutions enhances verification performance.