DT: Decision Transformer: Reinforcement Learning via Sequence Modeling

DT的核心:将强化学习问题转化为一个序列建模问题,并且使用Transformer来解决这个问题。直接绕过了TD-Learning等传统强化学习的方法。
Decision Transformer (DT) models offine trajectories extended with the sum of the future rewards along the trajectory, namely the return-to-go (RTG). RTG characterizes the quality of the subsequent trajectory, and DT learns to predict future actions given RTG. During testing, we deliberately provide DT with a high RTG to generate an above-average action.
算法
算法并不复杂,直接看伪代码:


训练的时候K个时间步会对应3K个Token,state、action、reward用的是不同的embedding网络,K个时间步对应K个位置编码。注意到推理的时候,每次都需要输入一个长度为K的轨迹片段,然后只取最后一个action作为输出(因此计算开销会比较大)。用的不是reward,而是RTG(Return-to-go)。
训练跟BC差不多,没有预测state和reward:
The prediction head corresponding to the input token is trained to predict – either with cross-entropy loss for discrete actions or mean-squared error for continuous actions – and the losses for each timestep are averaged. We did not find predicting the states or returns-to-go to be necessary for good performance.
测试:
Evaluation. During evaluation rollouts, we specify a target return based on our desired performance (e.g., specify maximum possible return to generate expert behavior) as well as the environment starting state, to initialize generation. After executing the generated action, we decrement the target return by the achieved reward and obtain the next state. We repeat this process of generating actions and applying them to obtain the next return-to-go and state until episode termination.
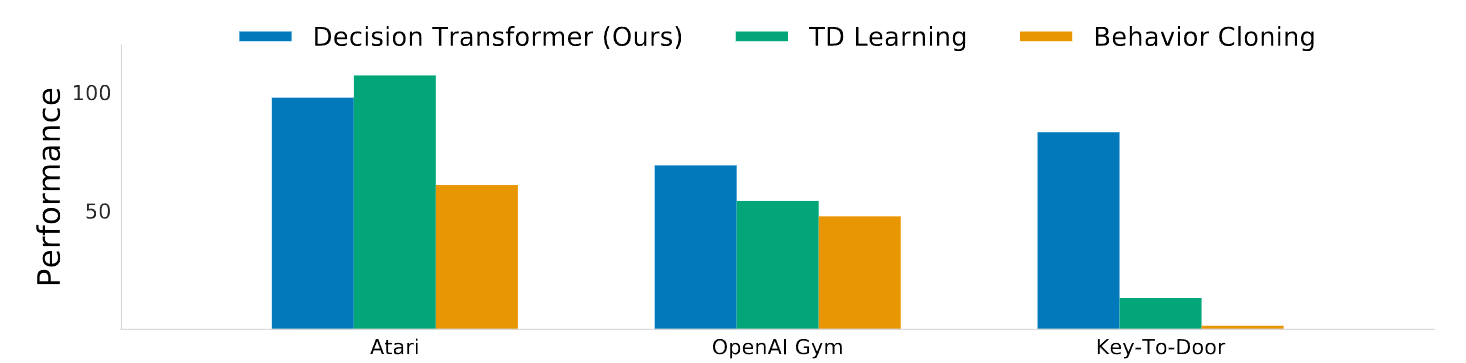
效果图: