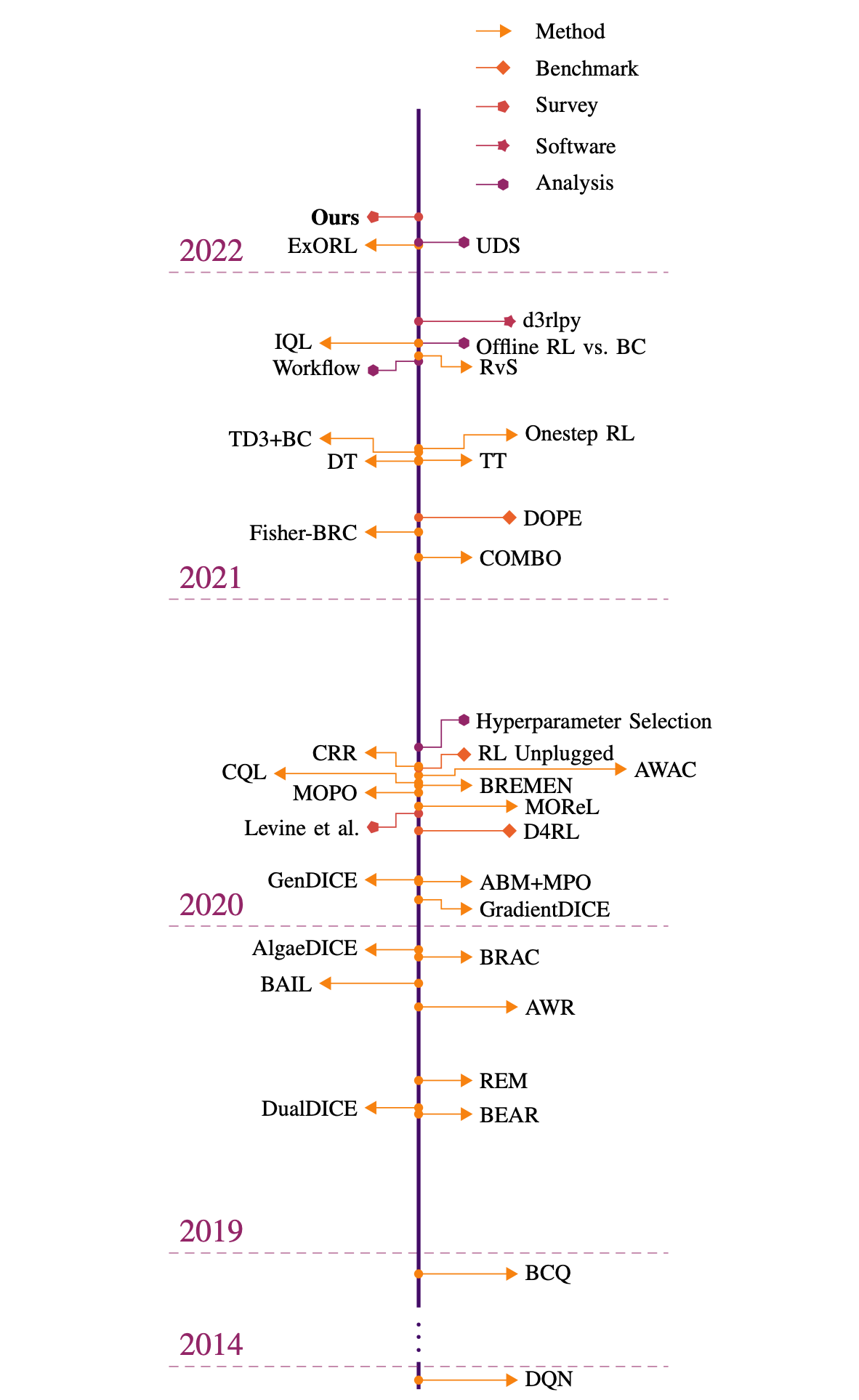
离线强化学习系列
Diffusion里面也有不少Offline RL的算法,我并没有将其放在本章节这里。
离线强化学习的算法大概可以分为以下四个类别: TBD:
领域内经典论文
- D4RL:
D4RL: Datasets for Deep Data-Driven Reinforcement Learning一个非常重要的离线强化学习的benchmark,需要掌握其用法。 - BCQ:
Batch-Constrained Q-learning - BEAR:
BEAR: Off-Policy Batch Deep Reinforcement Learning with Application to Robot Manipulation - BRAC:
BRAC: Bilevel Actor-Critic for Batch Deep Reinforcement Learning - CQL:
Conservative Q-Learning for Offline Reinforcement Learning - AWAC:
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets - IQL:
Implicit Quantile Networks for Distributional Reinforcement Learning - CORL:
CORL: Research-oriented Deep Offline Reinforcement Learning Library,综合实现了Offline RL的多个算法,代码非常简洁漂亮。
一些个人碎碎念
- 论文阅读一定要区分主次,要读的论文太多太多了,所以一定不能每一篇论文都按照同等的精力详细地看完,不能每一篇论文的代码都看。
- 不同论文的阅读方式也不相同
- 比如CQL这篇论文,我第一次读完之后,这周又重新翻回去看了看,同时在之前的基础上写了代码,调了一天的时候之后能够得到跟原论文一样的实验效果,这种需要精读的论文,需要螺旋式的方式不断深化理解
简单来说,不仅需要把论文读懂,还需要会实现,并且实现效果需要尽可能匹配论文结果。另一方面,不同算法之间的对比和关联,需要通过High-level的方式来理解,不要陷入细节。