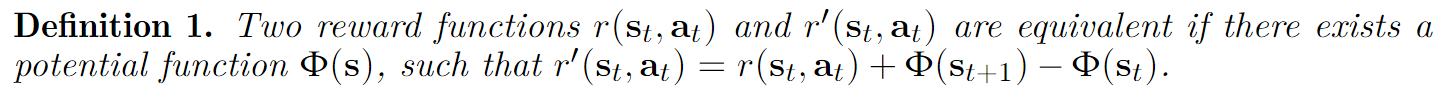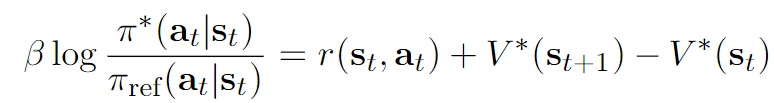From r to Q*: Your Language Model is Secretly a Q-Function
读这篇论文之前,请先阅读:
- DPO: Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- SQL: Reinforcement Learning with Deep Energy-Based Policies
Note:本文不会很详细地概述论文,主要是从逻辑线的角度寻求一个合理的视角,试图从作者的视角思考如何将r和Q*联系起来。
Motivation: logπref(yi∣[x,y<i])πθ(yi∣[x,y<i]) 是否可以等价于第i个token的reward?
先放出DPO的优化目标:
maxπθEx∼D,y∼πθ[rϕ(x,y)]−βDKL[πθ(y∣x)∥π(y∣x)]
通过上式子的闭式解带入BT-model得到DPO最终的Loss为:
L=−E(x,yw,yl)[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x)))]
在上一篇论文DPO中我们讲过可以简单地将整个回答看成是一个action,LLM执行一个action直接拿到一个sequence score。
DPO和核心的代码如下:
def preference_loss(policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
reference_chosen_logps: torch.FloatTensor,
reference_rejected_logps: torch.FloatTensor,
beta: float,
label_smoothing: float = 0.0,
ipo: bool = False,
reference_free: bool = False) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
"""Compute the DPO loss for a batch of policy and reference model log probabilities.
Args:
policy_chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
policy_rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
reference_chosen_logps: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
reference_rejected_logps: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
beta: Temperature parameter for the DPO loss, typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.
label_smoothing: conservativeness for DPO loss, which assumes that preferences are noisy (flipped with probability label_smoothing)
ipo: If True, use the IPO loss instead of the DPO loss.
reference_free: If True, we ignore the _provided_ reference model and implicitly use a reference model that assigns equal probability to all responses.
Returns:
A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).
The losses tensor contains the DPO loss for each example in the batch.
The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively.
"""
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
if reference_free:
ref_logratios = 0
logits = pi_logratios - ref_logratios
if ipo:
losses = (logits - 1/(2 * beta)) ** 2
else:
losses = -F.logsigmoid(beta * logits) * (1 - label_smoothing) - F.logsigmoid(-beta * logits) * label_smoothing
chosen_rewards = beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = beta * (policy_rejected_logps - reference_rejected_logps).detach()
return losses, chosen_rewards, rejected_rewards
def _get_batch_logps(logits: torch.FloatTensor, labels: torch.LongTensor, average_log_prob: bool = False) -> torch.FloatTensor:
"""Compute the log probabilities of the given labels under the given logits.
Args:
logits: Logits of the model (unnormalized). Shape: (batch_size, sequence_length, vocab_size)
labels: Labels for which to compute the log probabilities. Label tokens with a value of -100 are ignored. Shape: (batch_size, sequence_length)
average_log_prob: If True, return the average log probability per (non-masked) token. Otherwise, return the sum of the log probabilities of the (non-masked) tokens.
Returns:
A tensor of shape (batch_size,) containing the average/sum log probabilities of the given labels under the given logits.
"""
assert logits.shape[:-1] == labels.shape
labels = labels[:, 1:].clone()
logits = logits[:, :-1, :]
loss_mask = (labels != -100)
labels[labels == -100] = 0
per_token_logps = torch.gather(logits.log_softmax(-1), dim=2, index=labels.unsqueeze(2)).squeeze(2)
if average_log_prob:
return (per_token_logps * loss_mask).sum(-1) / loss_mask.sum(-1)
else:
return (per_token_logps * loss_mask).sum(-1)
从上面实际代码可以看出计算DPO损失时,因为y本身也是一个序列,序列出现的概率为每一个yi的概率的乘积,因此:
log(π(y∣x))=i=1∑Nlog(π(yi∣x))
带入DPO的Loss公式,得到:
L=−E(x,yw,yl)[logσ(βi=1∑N1logπref(ywi∣[x,yw<i])πθ(ywi∣[x,yw<i])−βi=1∑N2logπref(yli∣[x,yl<i])πθ(yli∣[x,yl<i])))]
看起来貌似是一个“token-level”的reward,但是在原来的DPO理论分析中并没有体现出来,于是我们在思考,假如我们从token reward的角度去分析DPO,那么是不是会有新的发现呢?
比如每一个token的reward是不是可以看成logπref(yt∣[x,ywi])πθ(yt∣[x,ywi])?答案是肯定的,但是这个推导并不trival。
Soft Q learning框架 + DPO
既然是token level reward了,那么最优化的目标也需要进行改写,下式中的st=[x,y<t]代表的是x和y中前t-1个token的concatenation:
θmaxEx∼D,y∼πθ[t=1∑Tr(st,yt)]−βDKL[πθ(y∣x)∥πref(y∣x)]=θmaxEx∼D,y∼πθ[t=1∑T[r(st,yt)+βlogπref(yt∣st)+βH(πθ(st))]]
将r(st,yt)+βlogπref(yt∣st)看成r′(st,yt),不考虑数据集上的期望x,考虑某一个具体的样本x,那么优化目标可以写成:
θmaxt=1∑TEyt∼πθ(st)[r′(st,yt)+βH(πθ(st))]
仔细一看这个目标,不正是Soft Q learning的Mat Ent RL的目标吗?
而根据SQL中的理论结果,最优策略必然会满足:
πθ∗(yt∣st)=exp(β1Q∗(st,yt)−β1V∗(st))
其中
Q∗(st,yt)=r′(st,at)+Eπ∗[k=t+1∑T(r′(sk,yk)+βH(π∗(sk)))]
V∗(st)=β∫exp(β1Q∗(st,yt))dyt
按照最优解的方程,我们有如下性质:
- 性质1,直接从Q∗的定义式反递归展开得到:
Q∗(st,yt)=r′(st,yt)+βH(π∗(st))+Eat+1∼π∗(st+1)[Q∗(st+1,yt+1)]
- 性质2:
Q∗(st,yt)=r′(st,yt)+V∗(st+1)
证明:
βH(π∗(st))+Eat+1∼π∗(st+1)[Q∗(st+1,yt+1)]展开即可得到V∗(st+1)的定义式。
于是乎,我们得到了如下的Q∗的另外一种表达式:
Q∗(st,yt)={r(st,yt)+βlogπref(yt∣st)+V∗(st+1)r(st,yt)+βlogπref(yt∣st)if yt≠EOSif yt=EOS
前面的推导其实完全是SQL中的若干公式的复写,而我们的最终目的是preference,所以还是需要将注意力回归到BT-model,而BT-model重心是∑t=1Tr(st,yt)的sigmoid下的比较。
t=1∑Tr(st,yt)=t=1∑T(Q(st,yt)−βlogπref(yt∣x)−V(st+1))=V∗(s1)+t=1∑Tβlogπref(yt∣x)πθ(yt∣x)
因此:
pπ∗(τw>τl)=σ(t=1∑Nβlogπref(ytw∣x)πθ(ytw∣st)−t=1∑Mβlogπref(ytl∣x)πθ(ytl∣x))
通过优化pπ∗(τw>τl),我们其实将π往π∗靠拢。
但是问题又来了,我们这个推导完全没办法知道r(st,at)的具体形式,也就是说它并不一定等于βlogπref(yt∣x)πθ(yt∣x)。只是说按照Q∗,V∗我们在计算∑t=1Tr(st,yt)恰好得到V∗(s1)+∑βlogπref(yt∣x)πθ(yt∣x),然后这个V∗(s1)在BT中被消掉了。
Reward shaping
第一个小节提出的问题是,为什么r(st,yt)可以等价于βlogπref(yt∣st)πθ(yt∣st)?
但是第二小节的推导又告诉我们,r(st,yt)的形式不一定是βlogπref(yt∣st)πθ(yt∣st)。
这一小节,我们从reward之间的等价性入手,说明使用logπref(yt∣x)πθ(yt∣x)作为token reward,与使用r(st,yt)作为token reward得到的最优策略是一样的。