Let’s Verify Step by Step

在《Let’s Verify Step by Step》中,作者探究了基于中间推理过程构建process reward model的方案和效果。具体而言,作者进行了以下工作:
- 以GPT4-Base Model为基础,在MATH数据集上构造了中间推理数据,并以该数据集来微调Base Model,得到可以生成中间推理步骤的Generator;
- 采用人工标注,对Generator生成的每个step的1个或多个推理步骤进行标注,“-1”、“0”、“1”分别代表“negative”、“neutral”、“positive”;
- 基于标注的中间推理数据来训练process reward model;
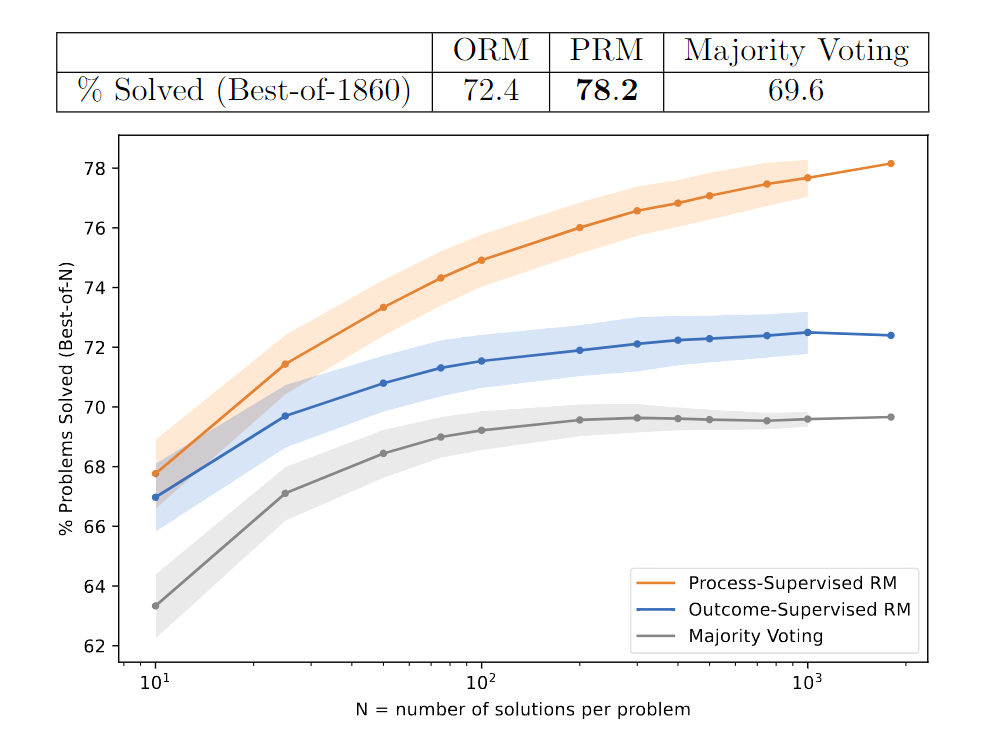
- 实验发现process supervision优于outcome supervision,具体而言在Best-of-N上性能更优秀、更不易饱和。
关于verifier,最简单的理解方式是把它看作ranker(排序模型),当generator生成多个候选solution(CoT形式),verifier对它们进行打分,此外,还可以从强化学习的角度把verifier看作reward model (把训练verifier类比为LLM post-training中的training reward model)。当我们从RL角度看待generator和verifier时,就容易理解outcome和process了,generator用于生成CoT, 这是一个token序列,如果问题很复杂,序列会很长,然后verifier对solution打分,这个分数就是reward,这种verifier就是outcome-supervised,用来监督整个CoT序列是否正确,由于一个序列只对应一个reward,明显是sparse reward,能不能用某种dense reward监督CoT序列的中间步骤呢?这就是process-supervised reward的insight,因为CoT包含了很多step(thought),我们对每个step都标注正确与否,然后训练能对step打分的verifier,得到PRM。
本文选用的LLM是base GPT-4,作者先创建了一个比较大的MathMix的数据集(1.5B token)对GPT-4 fine-tuning,提升数学理解能力。CoT本质上是token sequence,如何划分step(thought)呢?作者采用的方式是用"\n"符号,为了能让generator生成带有"\n"格式的CoT,作者用few-shot CoT引导LLM为MATH训练集生成带有\n的solution,然后过滤掉answer不对的,用剩下的数据对LLM fine-tuning,得到generator。
Note: 用\n格式的数据fine-tuning LLM,不是为了提升LLM的推理能力,更多的是为了让generator生成我们想要的solution格式,即\n区分step的格式,这样才能人工标注每个step。
下面就是一条标注事例,step的标注是一个三分类问题,作者认为单独设置一个neural类别(模棱两可的)的好处是在inference阶段可以根据使用场景,把它看作positive或者negative。

有了step标注数据,就可以训练PRM了,为了进一步提升训练集的质量(有些solution错误明显,用来训练verifier意义不大),假设现在已经有一个训练好的PRM(比如先标注1w条数据训练verifier),用PRM对generator刚生成的solution打分,专门挑选出那些answer错误但是PRM给出的step分数有很高的数据,这种属于hard样本,作者称为convincing wrong-answer solutions,让标注人员标注这批“高质量”的数据去训练verifier。
上面的过程【generator生成 --> PRM打分筛选 --> 人工标注 --> 训练verifier】迭代多次。
Note: 实际场景中,我们完全可以把训练generator也包含在迭代框架中,本文仅是为了对比PRM和ORM,所以假设得到generator后不再做参数更新了。
在训练PRM时,取每个step最后一个token的embedding预测当前step的分数,如果用来训练的solution是正确的,那么每个step的label都是positive(或neural),如果一条solution是错误的,那么至少有一个step是标注的negative,作者认为这条错误的step后面的steps就没有意义了,因为只会错误累计肯定都是错误的,所以把第一个错误的step后面的token删掉不参与训练。
直接看实验结果吧,PRM > ORM。