基本介绍
训练底层框架(这俩性能差不多):
- Deepspeed
- FSDP
推理框架:
- 原生Huggingface
- vLLM(主流)
- SGLang (势头强劲)
胜率测评
tatsu-lab/alpaca_eval数据集。原理很简单,就是提示词+api。
可以在训练过程中evaluate函数中进行胜率测评,并将胜率记录在wandb面板,方便监控,而不需要等到训练结束再做测评。
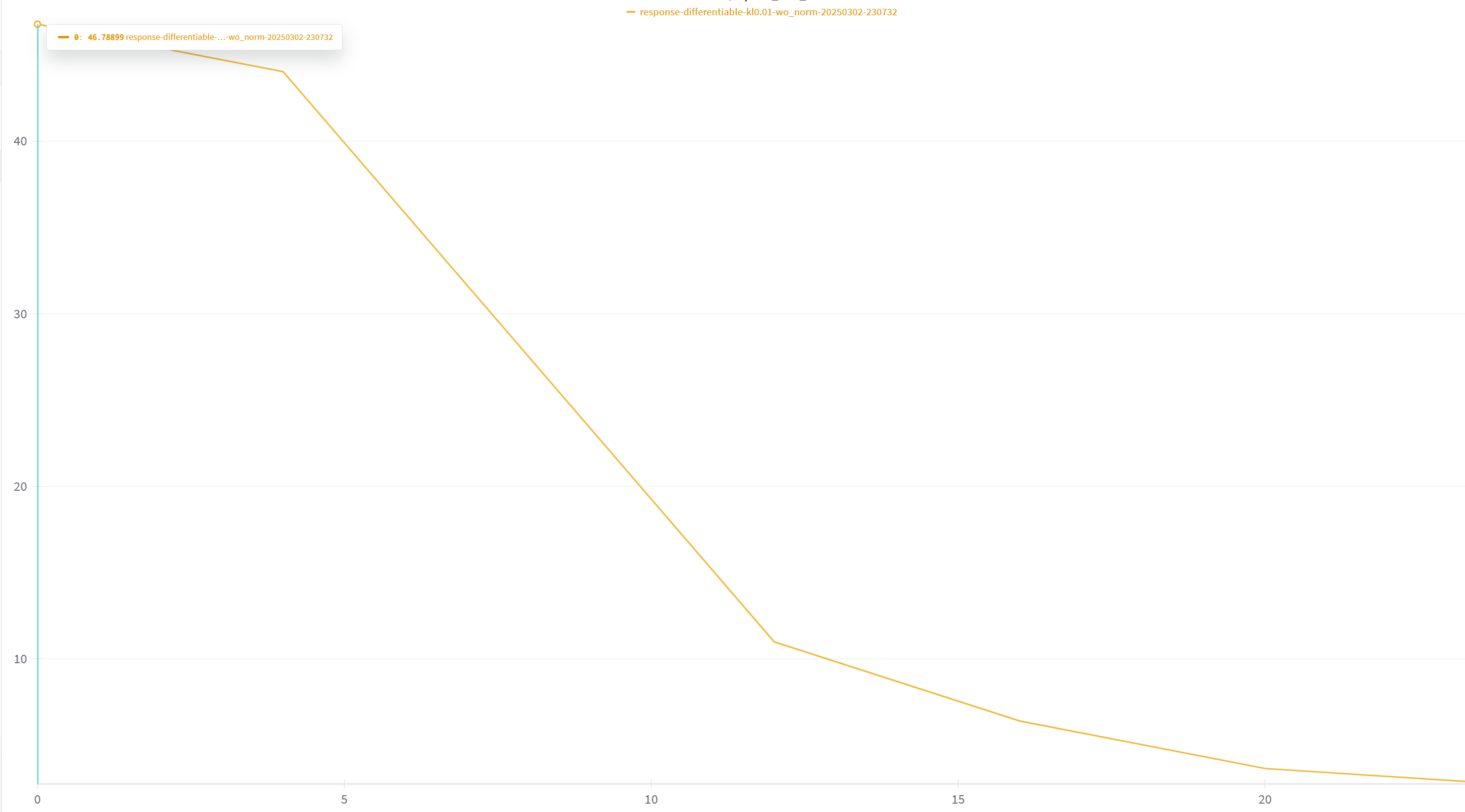
其他建议
- 建议每次训练都保存一个code snapshot,防止代码改的自己忘了
基础设施很重要,尽管确实费点时间,但是确实有用。
一些基础知识
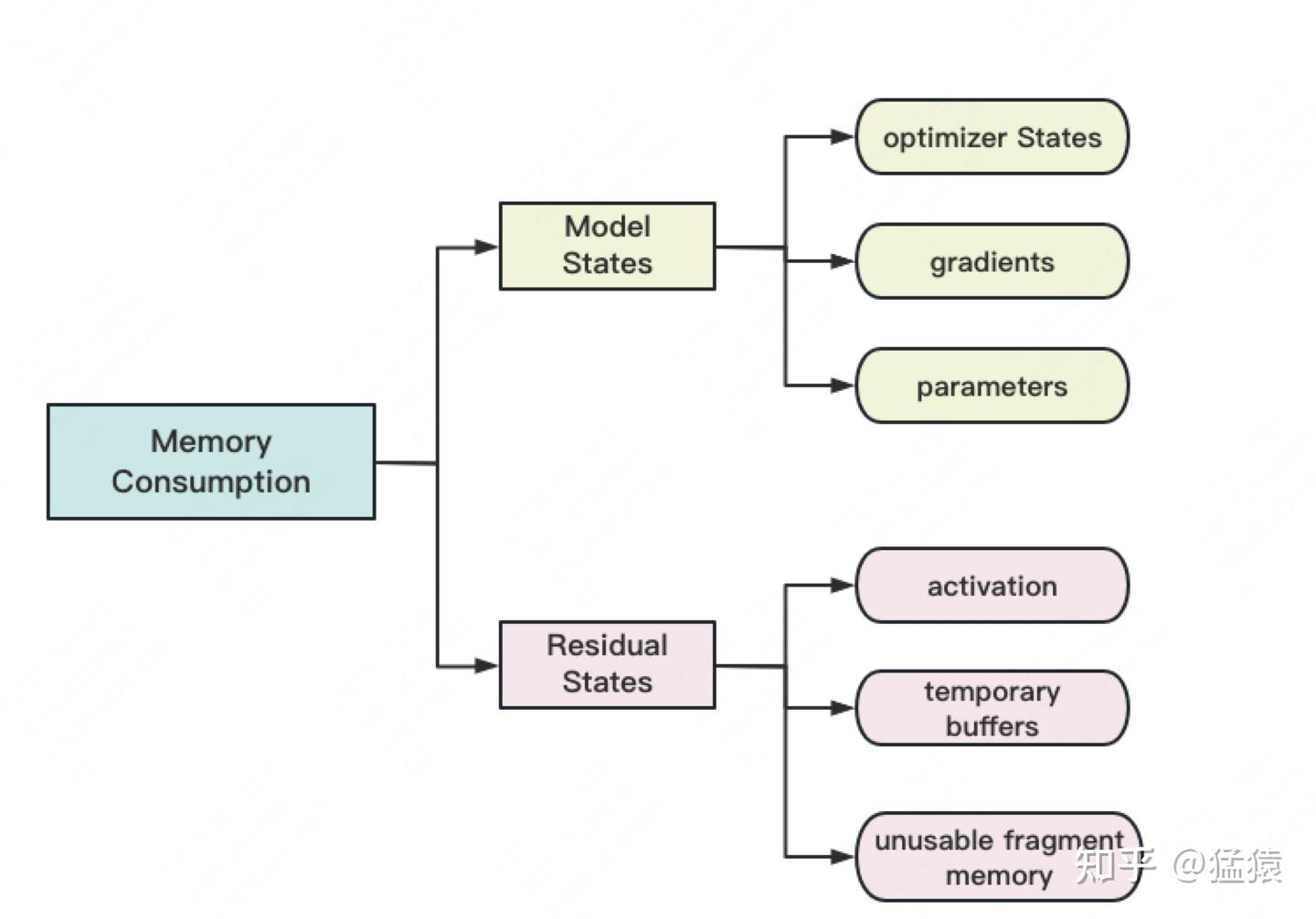
Model States指和模型本身息息相关的,必须存储的内容,具体包括:
- optimizer states:Adam优化算法中的momentum和variance
- gradients:模型梯度
- parameters:模型参数W
精度混合训练
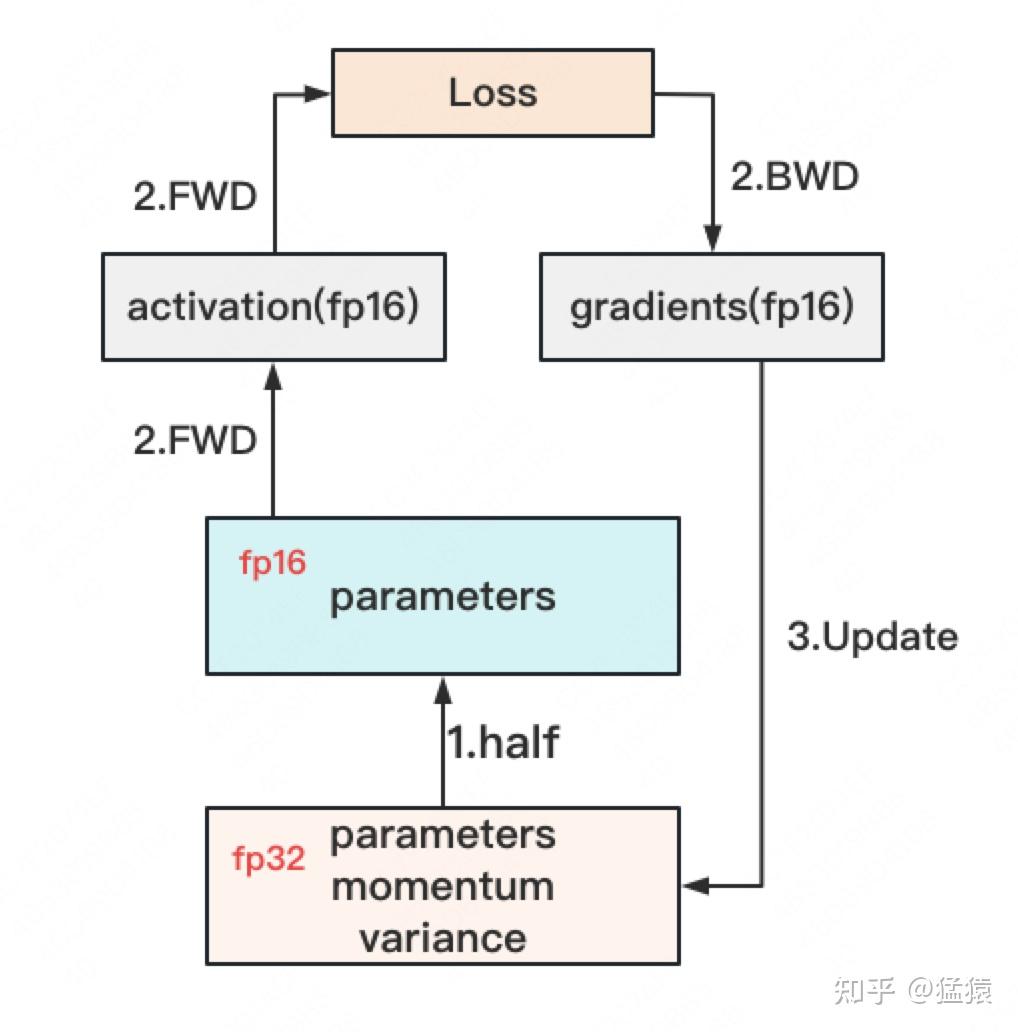
对于模型,我们肯定希望其参数越精准越好,也即我们用fp32(单精度浮点数,存储占4byte)来表示参数W。但是在forward和backward的过程中,fp32的计算开销也是庞大的。那么能否在计算的过程中,引入fp16或bf16(半精度浮点数,存储占2byte),来减轻计算压力呢?于是,混合精度训练就产生了,它的步骤如下图:
存储大小
假设模型的参数W大小是$\Phi$,以byte为单位,存储如下:

DP(DataParallel)
In DP, model parameters are replicated on each device. At each step, a mini-batch is divided evenly across all the data parallel processes, such that each process executes the forward and backward propagation on a different subset of data samples, and uses averaged gradients across processes to update the model locally.
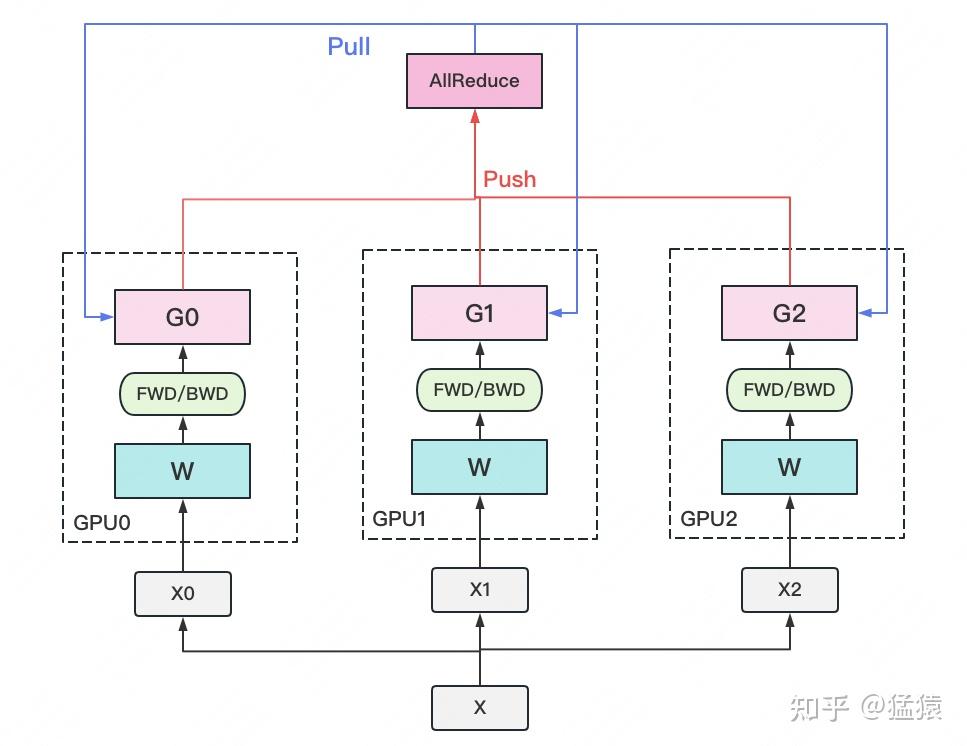
naive DP存在的问题:
- 单进程多线程模式,由于锁的机制导致线程间同步存在瓶颈。
- 使用普通的All-Reduce机制,所有的卡需要将梯度同步给0号节点,并由0号节点平均梯度后反向传播,再分发给所有其他节点,意味着0号节点负载很重。
- 由于2的原因,导致0号gpu通讯成本是随着gpu数量的上升而线性上升的。
- 不支持多机多卡。
DDP(Distributed Data Parallel)
前面DP的一个问题是中心节点的通讯负担很大,并且传输过程中其他节点就是在摸鱼,因此我们考虑去中心化。
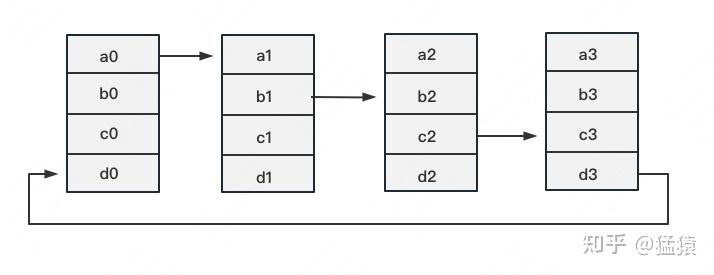
如下图,假设有4块GPU,每块GPU上的数据也对应被切成4份。AllReduce的最终目标,就是让每块GPU上的数据都变成箭头右边汇总的样子:

分为两个阶段(请仔细理解,后面会多次用到):
- Reduce-Scatter
- All-Gather
Reduce-Scatter 定义网络拓扑关系,使得每个GPU只和其相邻的两块GPU通讯。每次发送对应位置的数据进行累加。每一次累加更新都形成一个拓扑环,因此被称为Ring。
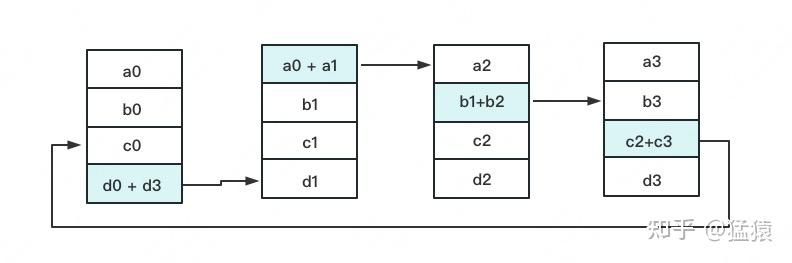
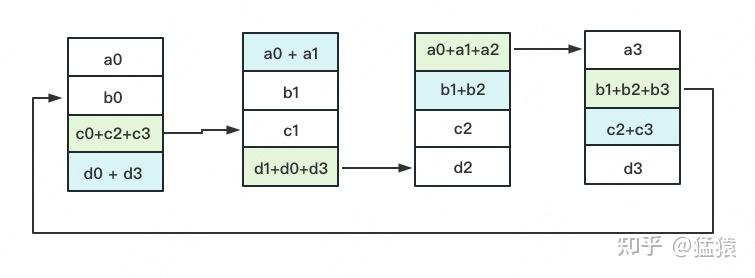

All-Gather
如名字里Gather所述的一样,这操作里依然按照“相邻GPU对应位置进行通讯”的原则,但对应位置数据不再做相加,而是直接替换。All-Gather以红色块作为起点。
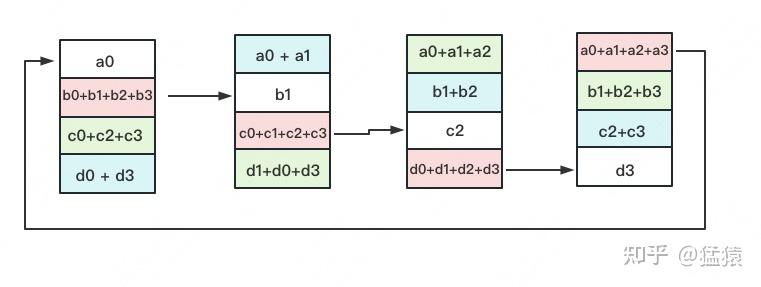
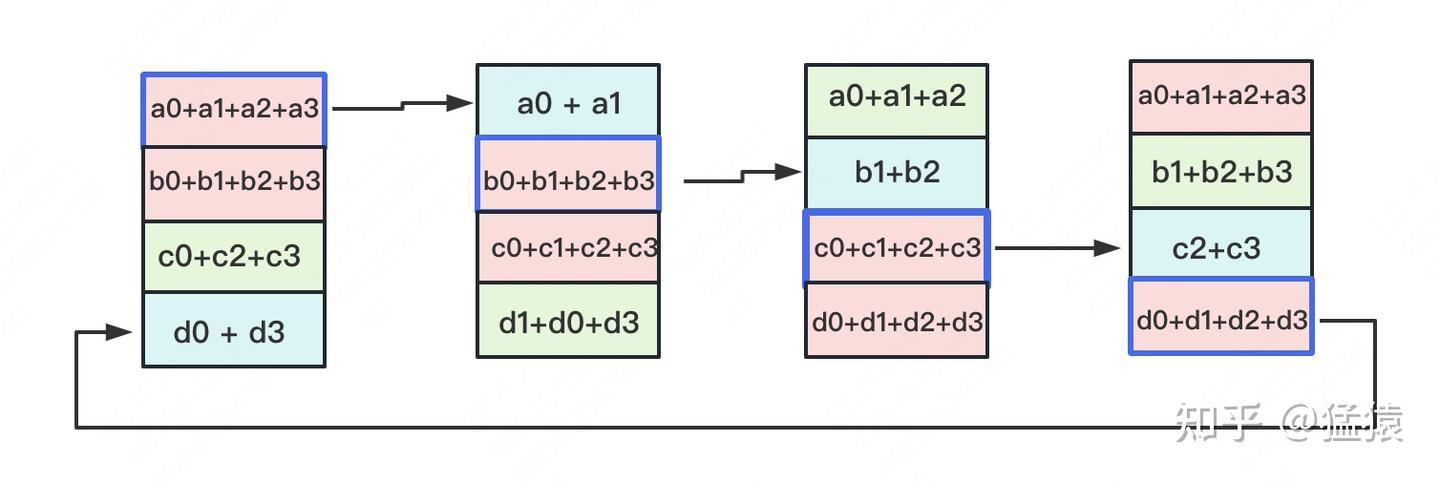
现在我们来计算一下单卡的传输量:
- Reduce-Scatter阶段:$(N-1)\frac{\Phi}{N}$
- All-Gather阶段:$(N-1)\frac{\Phi}{N}$
随着N的增大,可以近似为$2\Phi$,全卡的通信量为$2N\Phi$。
一个问题: Ring-AllReduce会减少DP总的通信量吗?
相对前文的DP来说,它的Server承载的通讯量是$N\Phi$,Workers为$N\Phi$,全卡总通讯量依然为$2N\Phi$。虽然通讯量相同,但搬运相同数据量的时间却不一定相同。DDP把通讯量均衡负载到了每一时刻的每个Worker上,而DP仅让Server做勤劳的搬运工。当越来越多的GPU分布在距离较远的机器上时,DP的通讯时间是会增加的。
Deepspeed ZeRO
下面的内容参考自知乎的,墙裂推荐阅读:

Zero
DP以及DDP在数据并行时,模型、梯度、优化器状态同时存在于多张卡中,这带来了数据冗余。微软的佬们从冗余的角度提出了零冗余优化(ZeRO、ZEro Redundancy Optimization)
注意到在训练过程中,有很多状态并不会每时每刻都用到,比如:
- 优化器状态、梯度只在反向传播时才需要;
- 参数只在做前向传播和反向传播的那一刻才用到。故ZeRO的做法就是数据用完即丢,需要时再从其他地方获取。
以通信开销换显存
ZeRO-1: Shards optimizer states across data parallel workers/GPUs
将优化器的状态分散到各个GPU上,具体来说,比如我现在3个GPU:
- 每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各保存一份,做完一轮foward和backward后,各得一份梯度G1, G2, G3$(G1\not=G2\not=G3)$。
- 对梯度做一次AllReduce,每个GPU得到完整的梯度G,产生单卡通信量$2\Phi$
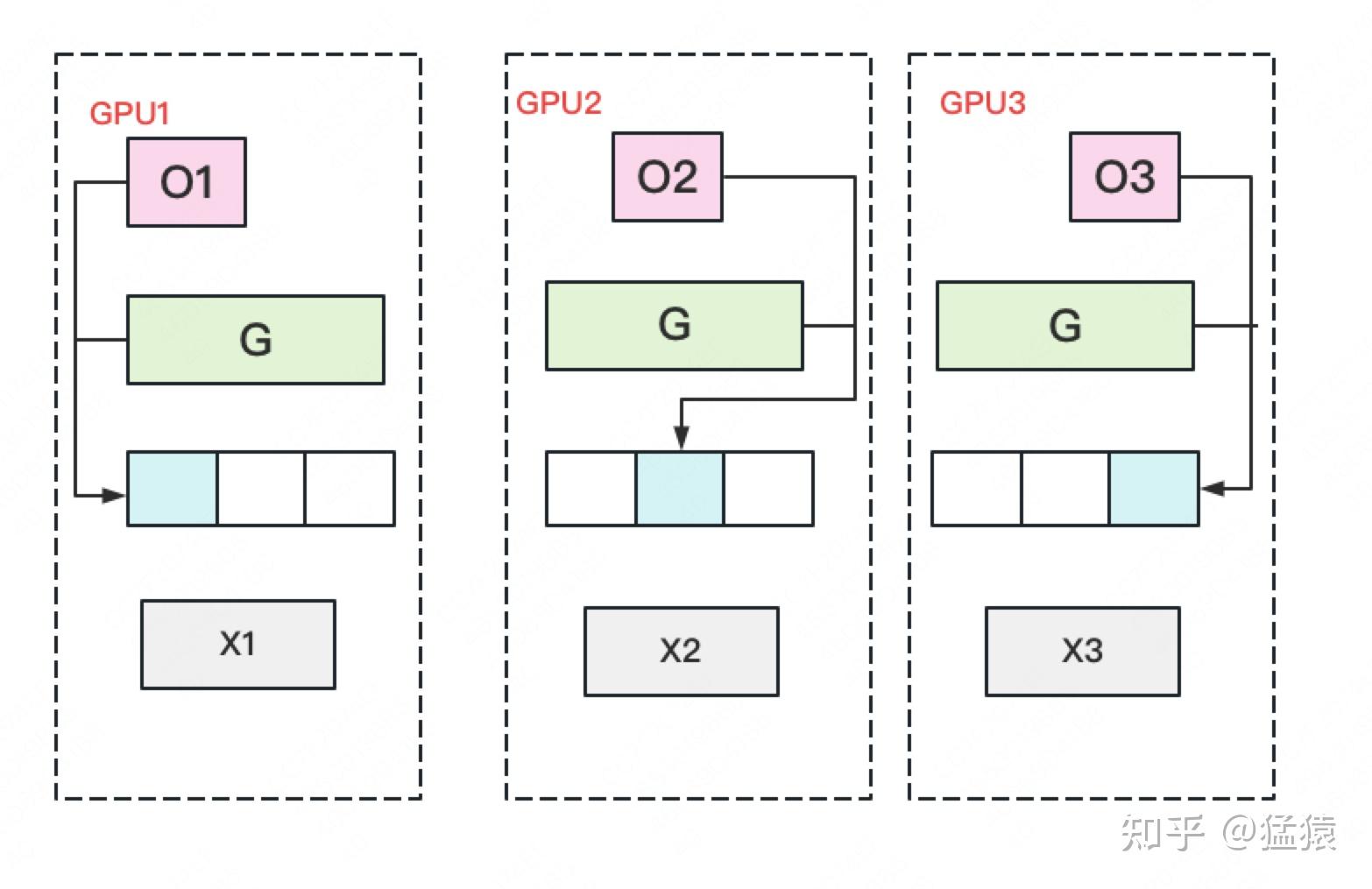
- 得到完整梯度G后,就可以对W做更新。由于W的更新由optimizer states和梯度共同决定。由于每块GPU上只保管部分optimizer states,因此只能将部分W(下图蓝色部分)进行更新。
- 此时,每块GPU上都有部分W没有完成更新(图中白色部分)。所以我们需要对W做一次All-Gather,从别的GPU上把更新好的部分W取回来。产生单卡通讯量$\Phi$
因此,Zero1的每次更新的单卡通信量为$3\Phi$。
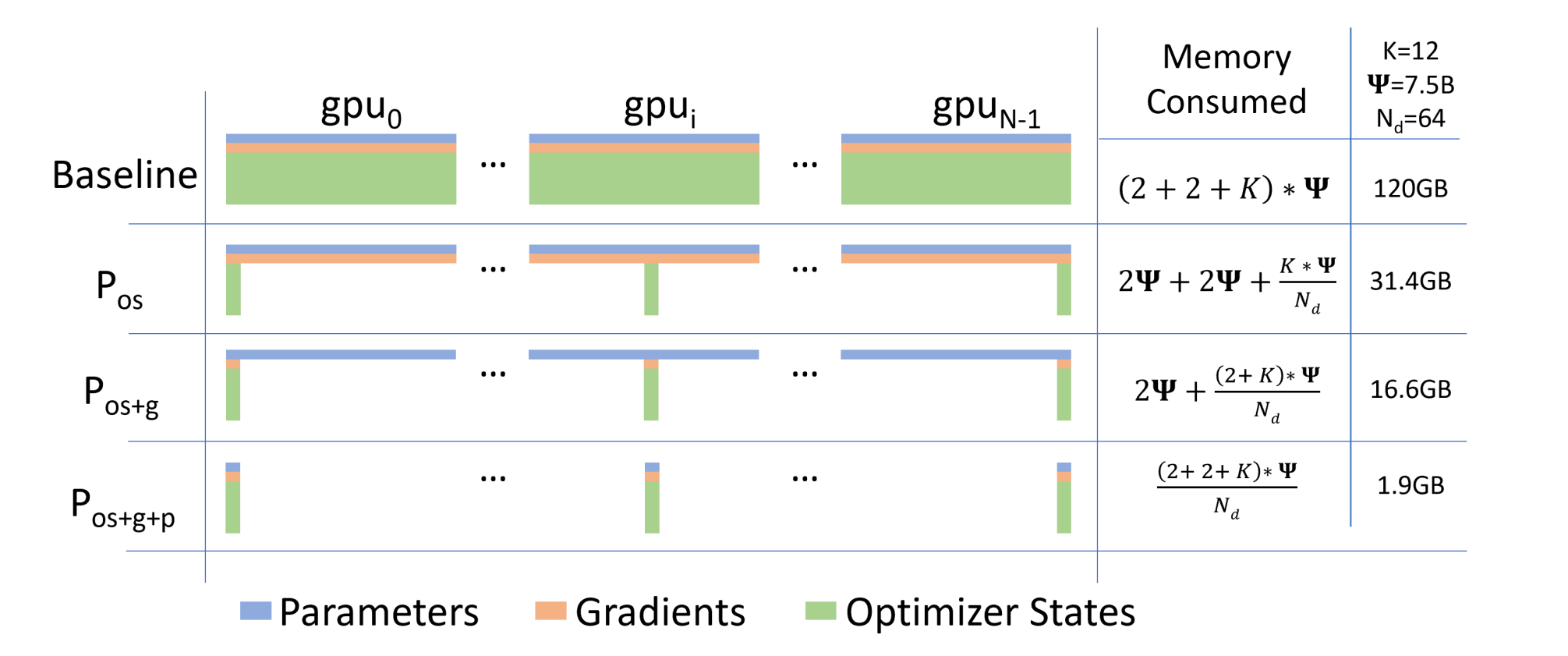
| 显存 | 显存(单位GB)$K=12, \Phi=7.5B, N_d=64$ | 单卡通讯量 | |
|---|---|---|---|
| 朴素DP | $(2+2+K)\Phi$ | 120GB | $2\Phi$ |
| $P_{os}$ | $(2+2+\frac{K}{N_d})\Phi$ | 31.4GB | $3\Phi$ |
实操中,$P_{os}$单卡通信量为$2\Phi$,思考一下这是为什么?
ZeRO-2: Shards optimizer states + gradients across data parallel workers/GPUs
现在,更近一步,我们把梯度也拆开,每个GPU格子维护一块梯度。那么每个GPU只需要$(2+\frac{2+K}{N_d})\Phi=16.6GiB$显存。
(1)每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮foward和backward后,算得一份完整的梯度(下图中绿色+白色)。

(2)对梯度做一次Reduce-Scatter,保证每个GPU上所维持的那块梯度是聚合梯度。例如对GPU1,它负责维护G1,因此其他的GPU只需要把G1对应位置的梯度发给GPU1做加总就可。汇总完毕后,白色块对GPU无用,可以从显存中移除。单卡通讯量$\Phi$。
注意此时每张卡并不拥有整个参数量的梯度,但是自己维护的那部分梯度是完整由所有的gpu累加起来的。
回顾:Reduce-Scatter

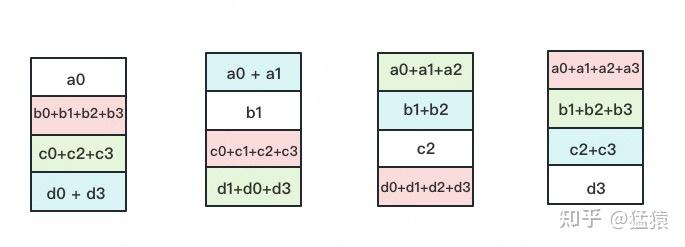
每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次All-Gather,将别的GPU算好的W同步到自己这来。单卡通讯量$\Phi$。
| 显存 | 显存(单位GB)$K=12, \Phi=7.5B, N_d=64$ | 单卡通讯量 | |
|---|---|---|---|
| 朴素DP | $(2+2+K)\Phi$ | 120GB | $2\Phi$ |
| $P_{os}$ | $(2+2+\frac{K}{N_d})\Phi$ | 31.4GB | $3\Phi$ |
| $P_{os+g}$ | $(2+\frac{K+2}{N_d})\Phi$ | 16.6GB | $2\Phi$ |
和朴素DP相比,存储降了8倍,单卡通讯量持平,好像更牛皮了呢!那么,还可以优化吗?
Zero-3: Shards optimizer states + gradients + model parameters across data parallel workers/GPUs
看到这里,也许你有点感觉了,ZeRO的思想就是:万物皆可切,万物皆可抛。所以现在,我们把参数也切开。每块GPU置维持对应的optimizer states,gradients和parameters(即W)。
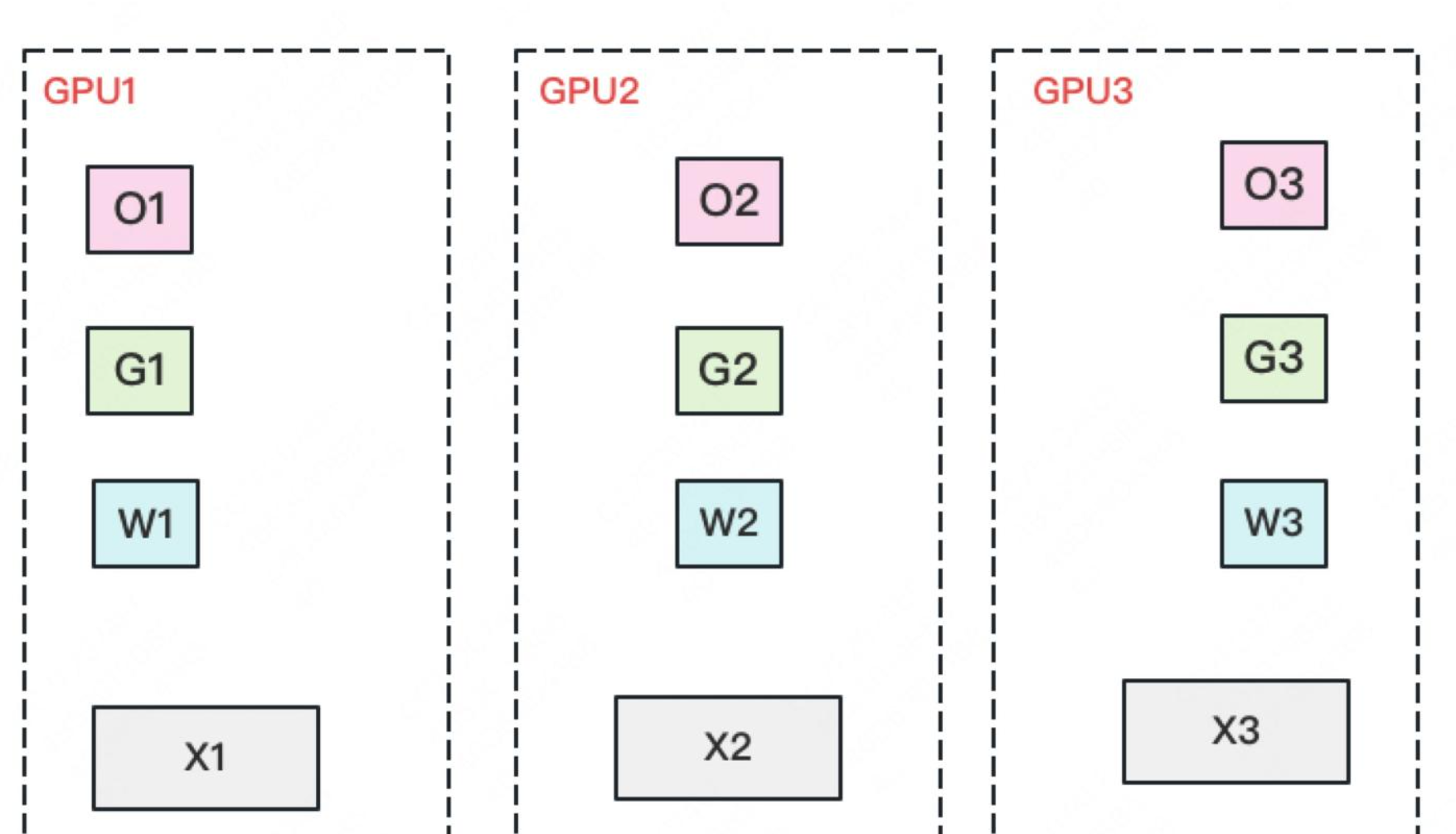
(1)每块GPU上只保存部分参数W。将一个batch的数据分成3份,每块GPU各吃一份。 (2)做forward时,对W做一次All-Gather,取回分布在别的GPU上的W,得到一份完整的W,单卡通讯量$\Phi$。forward做完,立刻把不是自己维护的W抛弃。 (3)做backward时,对W做一次All-Gather,取回完整的W,单卡通讯量$\Phi$。backward做完,立刻把不是自己维护的W抛弃。 (4)做完backward,算得一份完整的梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度,单卡通讯量$\Phi$。聚合操作结束后,立刻把不是自己维护的G抛弃。 (5)用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何AllReduce操作。
| 显存 | 显存(单位GB)$K=12, \Phi=7.5B, N_d=64$ | 单卡通讯量 | |
|---|---|---|---|
| 朴素DP | $(2+2+K)\Phi$ | 120GB | $2\Phi$ |
| $P_{os}$ | $(2+2+\frac{K}{N_d})\Phi$ | 31.4GB | $3\Phi$ |
| $P_{os+g}$ | $(2+\frac{K+2}{N_d})\Phi$ | 16.6GB | $2\Phi$ |
| $P_{os+g+p}$ | $(\frac{K+2+2}{N_d})\Phi$ | 1.9GB | $3\Phi$ |
总结一下:
Optimizer Offload: Offloads the gradients + optimizer states to CPU/Disk building on top of ZERO Stage 2
Param Offload: Offloads the model parameters to CPU/Disk building on top of ZERO Stage 3
参考论文:


FSDP
FSDP 全称 FullyShardedDataParallel, 是Meta 提出的一个针对LLM 训练的解决方案,它是一个数据并行的策略,通过对模型参数(parameters), 梯度(gradients)和优化器状态(optimizer states)在多gpu上点切分实现并行。API十分简单易用
下面是拷贝过来的,仅作为介绍,不需要刻意理解下面这段:
FSDP受启发于DeepSpeed ZeRO-DP,并进行了进一步的延申和拓展。首先回顾一下ZeRO-DP,根据切分的model states不同,ZERO可以分成3个阶段:ZeRO1(只对optimizer states切分);ZERO2 (对optimizer states和gradients切分),ZERO3(对optimizer states,gradients,parameters切分)。
相应的,FSDP包括了NO_SGARD(等效于DDP);SHARD_GRAD_OP(对标ZeRO2);FULL_SHARD (对标ZeRO3);HYBRID_SHARD(Node内shard,node间replicate,对标ZeRO++ stage3),同时还有_HYBRID_SHARD_ZeRO2(node内ZeRO2 shard,node间replicate)。
看看伪代码就好理解多了:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i
forward pass for layer_i
discard full weights for layer_i
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i
backward pass for layer_i
discard full weights for layer_i
reduce-scatter gradients for layer_i
我们发现,在for循环里面的执行的流程都比较固定,这样的流程的执行单元是一个unit,并不一定是整个模型的全部参数。这个unit可以是模型的一个layer,一个stage,一组layer (nn.Module),比如我们在Llama中常用的就是LlamaDecoderLayer。这个unit的design,就是FSDP的核心,它决定了计算和通信的执行单元。
总结一下:
- Constructor: 对模型参数进行切片分发到每个rank上
- Forward pass: 对每个FSDP unit,运行all_gather收集所有rank上的模型参数切片,这样每个rank上拥有当前unit的全部参数 (这也是为什么FSDP 仍然属于数据并行的原因,虽然对模型参数进行了切分,但是计算的时候还是用原始的全部参数来计算的,而不是像tensor parallel那样只拿weight的分片计算)
- 执行前向计算过程后丢掉不属于当前rank的模型参数,释放memory
- Backward pass: 反向传播过程中,FSDP同样需要收集完整的参数分片进行计算,并通过reduce-scatter 操作将梯度分片,每个GPU只负责更新自己负责的部分参数
- Optimizer updates: 每个 rank 对属于自己的局部梯度的分片进行更新
ok,我们现在来分析一下峰值显存占用:
假设模型的总参数量为$\Phi$,分成了N个unit:$\Phi_1, \Phi_2, \cdots, \Phi_N$,同时被分散到F个rank上面。
每个rank或者说每个gpu必须持有$\frac{\Phi}{F}$的参数。同时在forward或者backward时,会持有$max_{i=1}^N\Phi_{i}$的参数量。因此峰值为$O(\frac{\Phi}{F} + max_{i=1}^N\Phi_{i})$
vLLM (Virtual Large Language Model)
KV-Cache
典型的自回归式的生成
生成式generative模型的推理过程很有特点,我们给一个输入文本,模型会输出一个回答(长度为N),其实该过程中执行了N次推理过程。即GPT类模型一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
model = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "遥遥"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, _ = model(in_tokens)
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = torch.cat((in_tokens, out_token), 0)
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text = tokenizer.decode(in_tokens)
回顾一下大家熟悉不过的self-attention
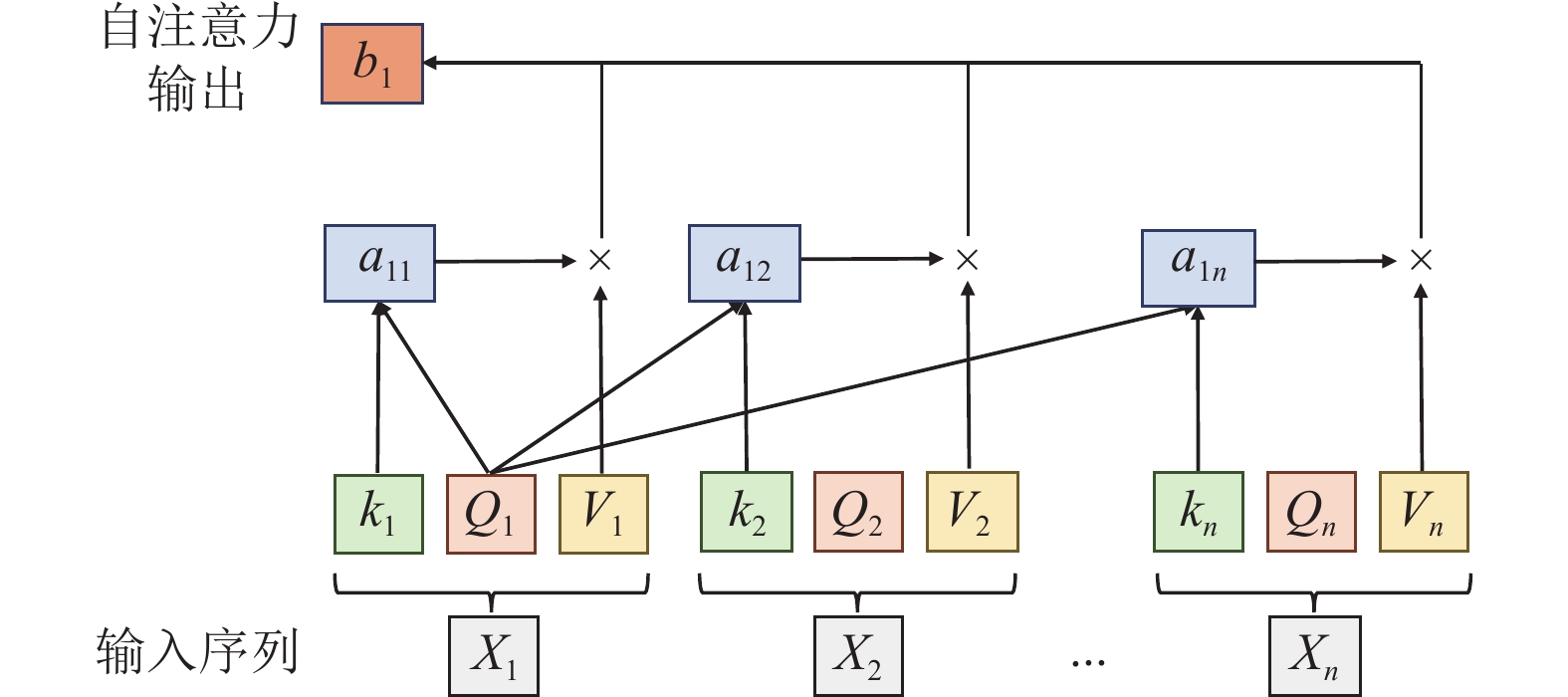
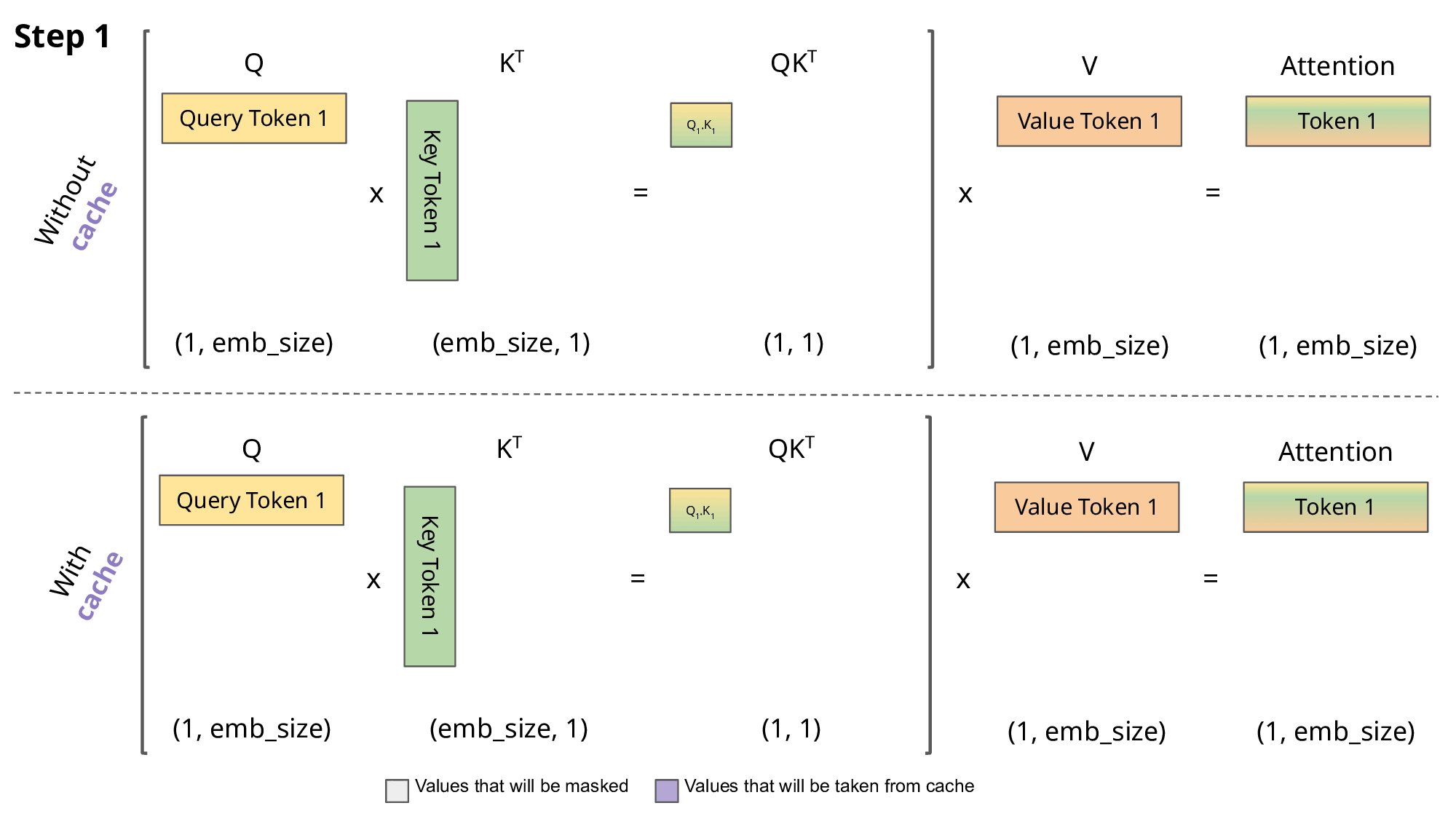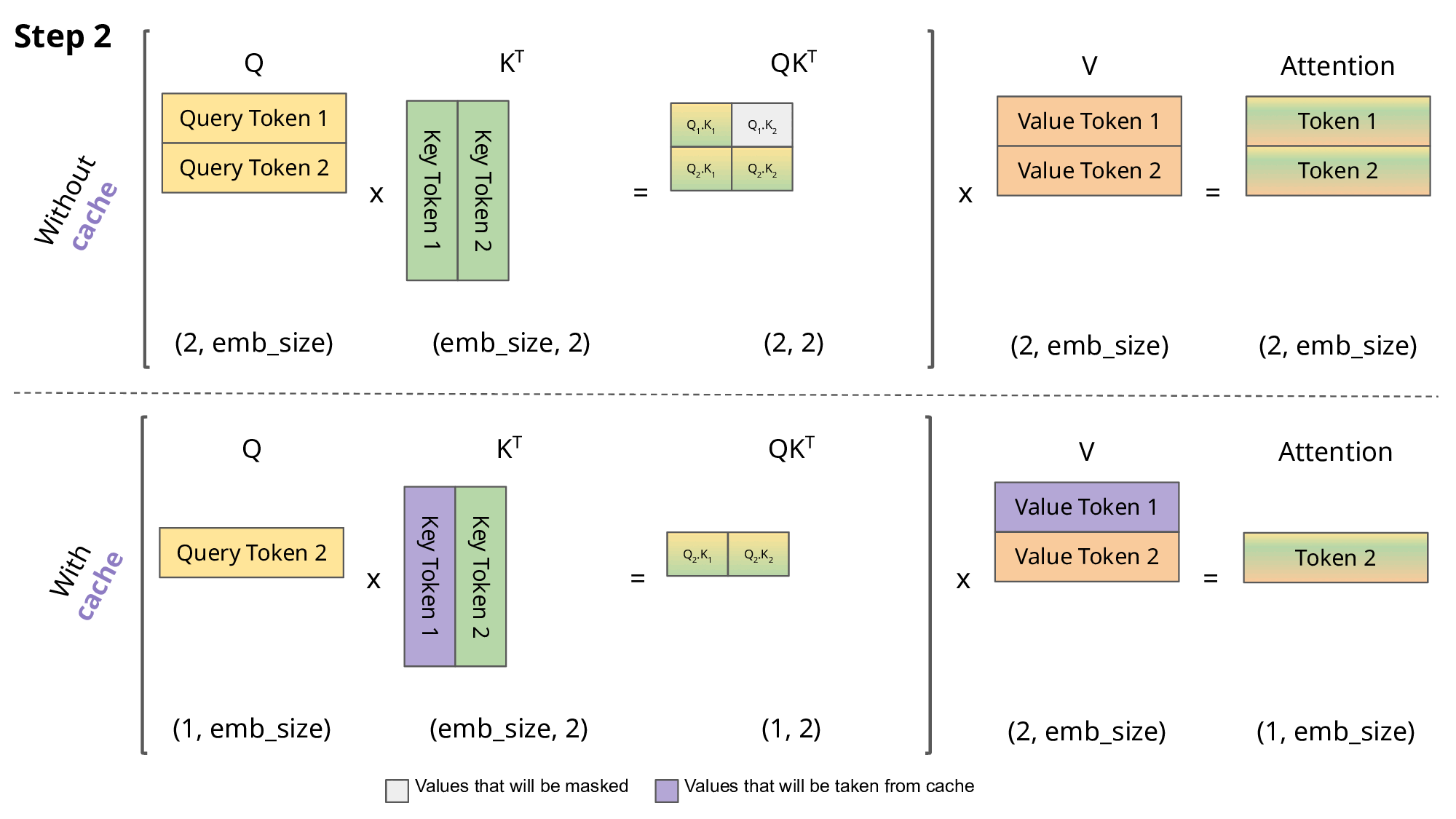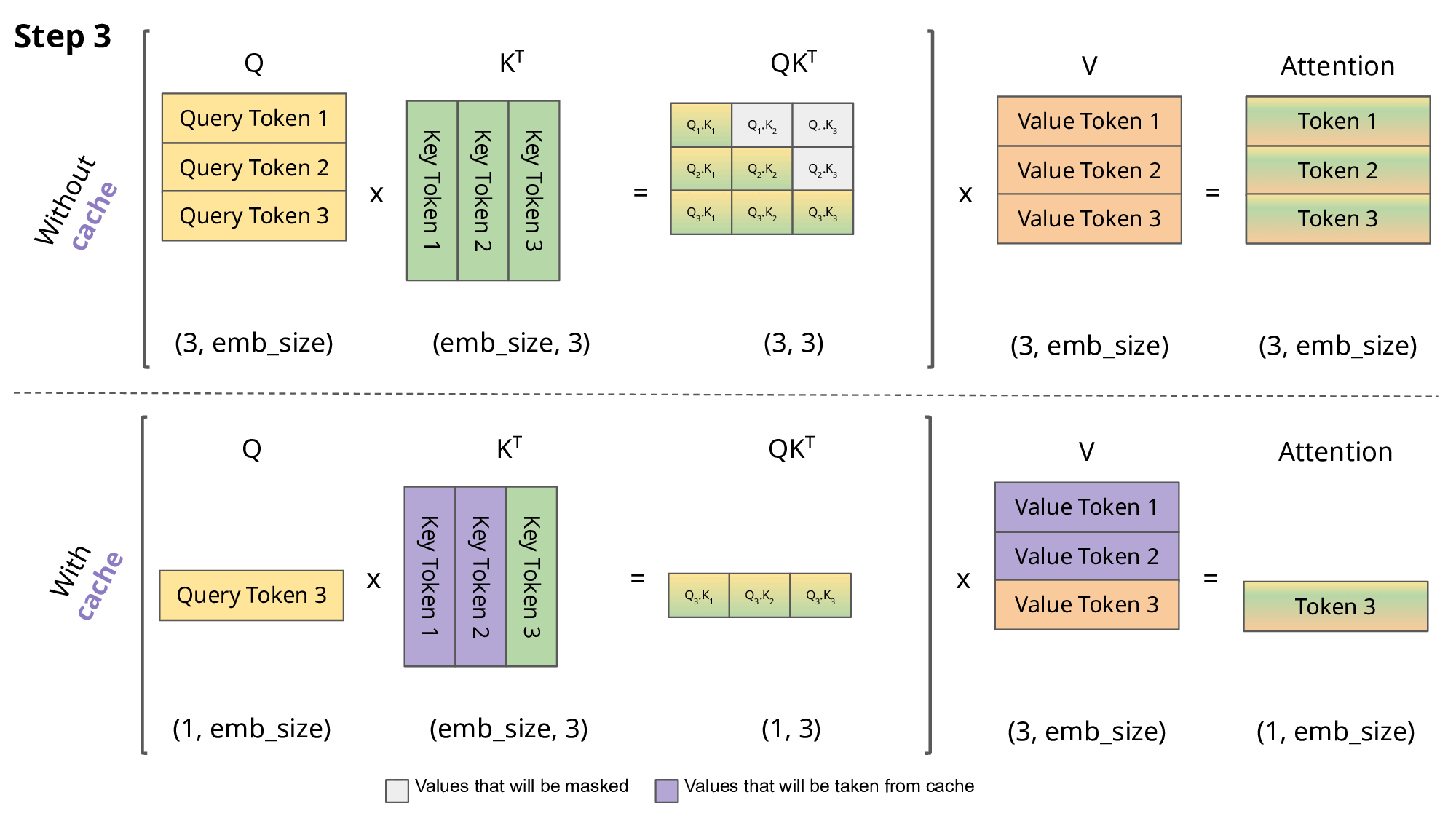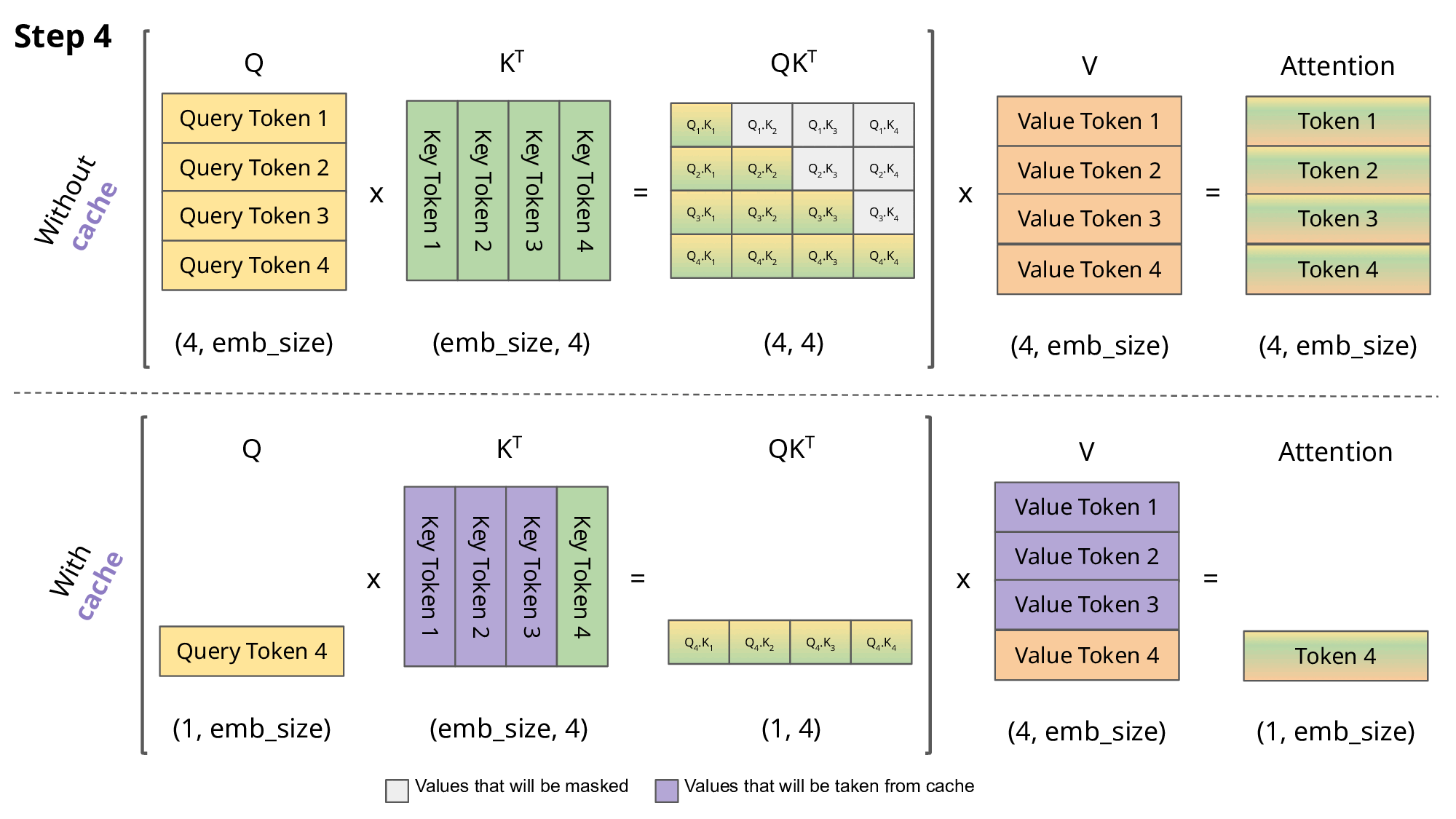
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第$i+1$轮输入数据只比第$i$轮输入数据新增了一个token,其他全部相同!因此第$i+1$轮推理时必然包含了第$i$轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果,就是这么简单,不存在什么Cache miss问题。
好了,那我们重复计算了什么?
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, kvcache = model(in_tokens, past_key_values=kvcache) # 增加了一个 past_key_values 的参数
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = out_token # 输出 token 直接作为下一轮的输入,不再拼接
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text += text
Q:为什么叫KV-Cache,Q在这个过程中会被缓存吗?
以13B的模型为例,在推理时,参数占用26G的显存,约为65%。KV cache占12G的显存约为30,剩下的是其他的系统占用。

我们可以来估算一下一个生成请求所需要的KV-Cache的大小:
The KV Cache size grows quickly with the number of requests. As an example, for the 13B parameter OPT model, the KV cache of a single token demands 800KB of space, calculated as 2 (key and value vectors) × 5120(hidden state size) × 40 (number of layers) × 2 (bytes perFP16). Since OPT can generate sequences up to 2048 tokens, the memory required to store the KV cache of one request can be as much as 1.6 GB.
我们瞬移一下来复习一下操作系统的基础
内部碎片:
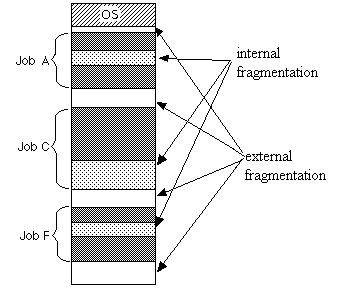
内部碎片是由于系统分配给进程的空间大于其所申请的大小,处于(操作系统分配的用于装载某一进程的内存)区域内部或页面内部的存储块,占有这些区域或页面的进程并不使用这个存储块。而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。
外部碎片:
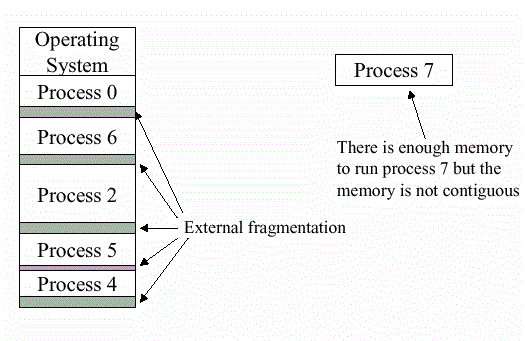
外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域,即处于任何两个已分配区域或页面之间的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
现代OS的比较成熟的内存管理机制是:段页式存储管理方式
分段机制不提了,简要介绍一下分页机制:
早期的KV-Cache内存管理系统存在的问题
早期的KV-Cache内存管理系统是连续的物理显存分配系统。
一个例子:

请求A的最大序列长度为2048,请求B的最大序列长度为512。
在常规的推理框架中,当我们的服务接收到一条请求时,它会为这条请求中的prompts分配gpu显存空间,其中就包括对KV cache的分配。由于推理所生成的序列长度大小是无法事先预知的,所以大部分框架会按照(batch_size, max_seq_len)这样的固定尺寸,在gpu显存上预先为一条请求开辟一块连续的矩形存储空间。然而,这样的分配方法很容易引起"gpu显存利用不足"的问题,进而影响模型推理时的吞吐量。
在这个例子里面:
- 内部碎片是因为高估了max_seq_len导致的
- 外部碎片则是因为内存allocator分配的一些性质,比如只能从某个2的幂次地址开始分配(Buddy System)导致的,这个确实没办法避免
行,解释完KV-Cache的重要性,我们需要讲一下早期的KV-Cache的分配系统存在的一些问题

所以很简单:提高显存利用效率和推理效率的方式:减少内外部碎片,这个其实借鉴了操作系统的一些处理方式,核心是PageAttention。
给个例子你就明白了:
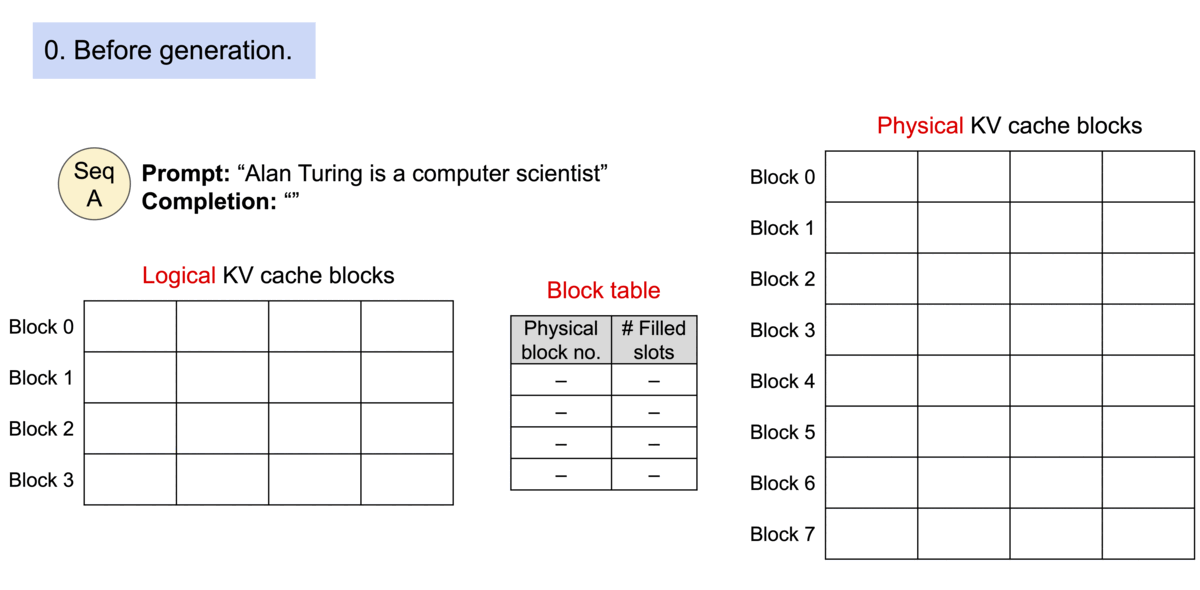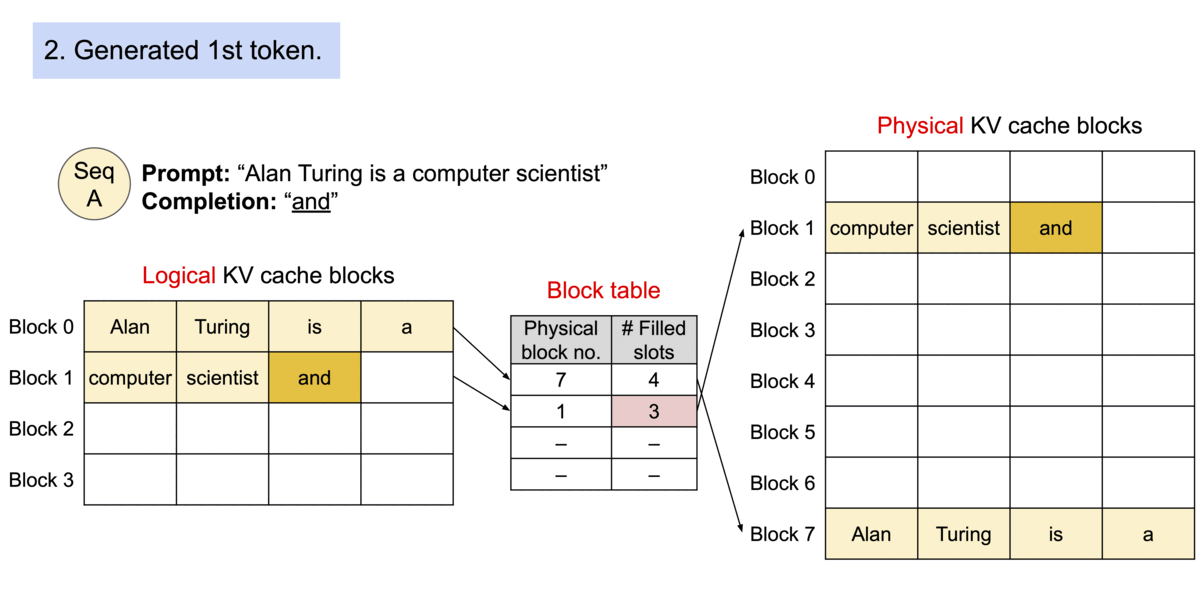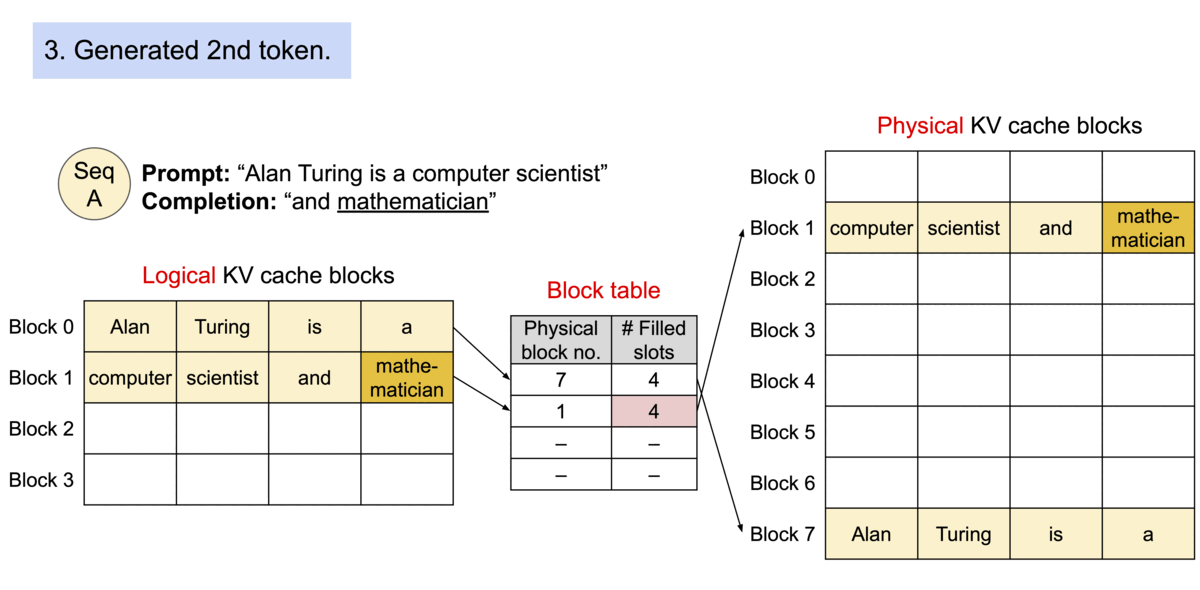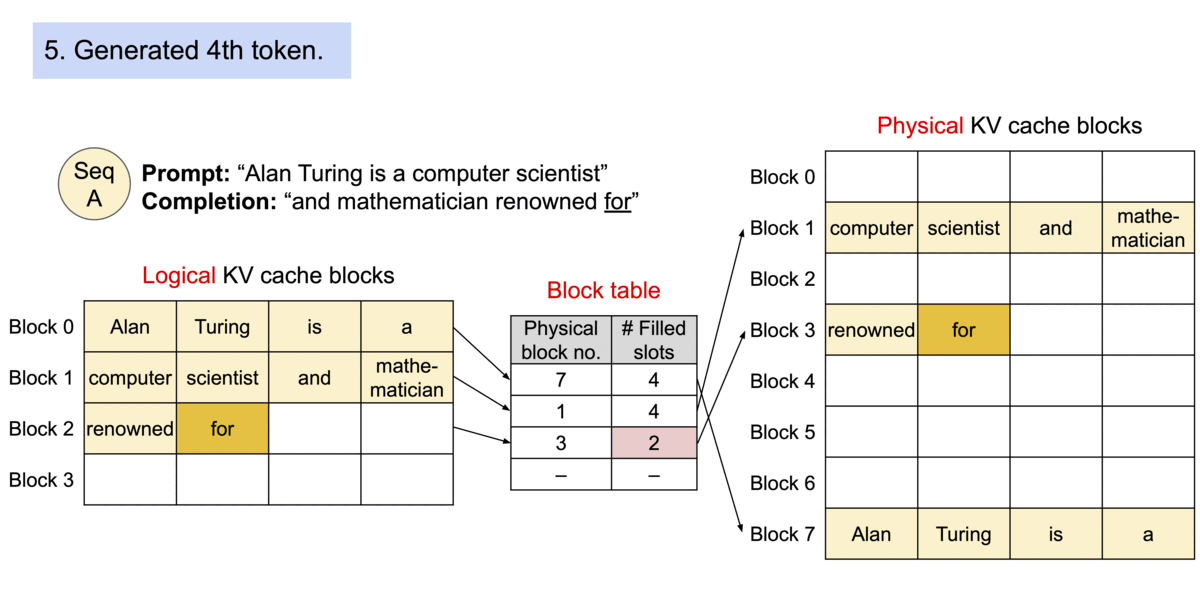
总结一下,核心思想就是每个请求都有一个逻辑的KV cache,在逻辑KV Cache里,显存好像是连续的,vLLM的框架会在后台维护一个逻辑KV Cache到实际显卡显存上KV Block的映射表,在进行page attention计算时,它会自动找到物理显存上block的KV向量进行计算,每个请求都有自己的逻辑KV cache,其中的prompt和生成的新的token的KV向量,看起来好像都是放在连续的显存上,方便程序操作。vLLM框架内部维护了映射表,在page attention进行计算时,获取实际显卡上的KV block里的KV向量。
Manage KV cache like OS virtual memory
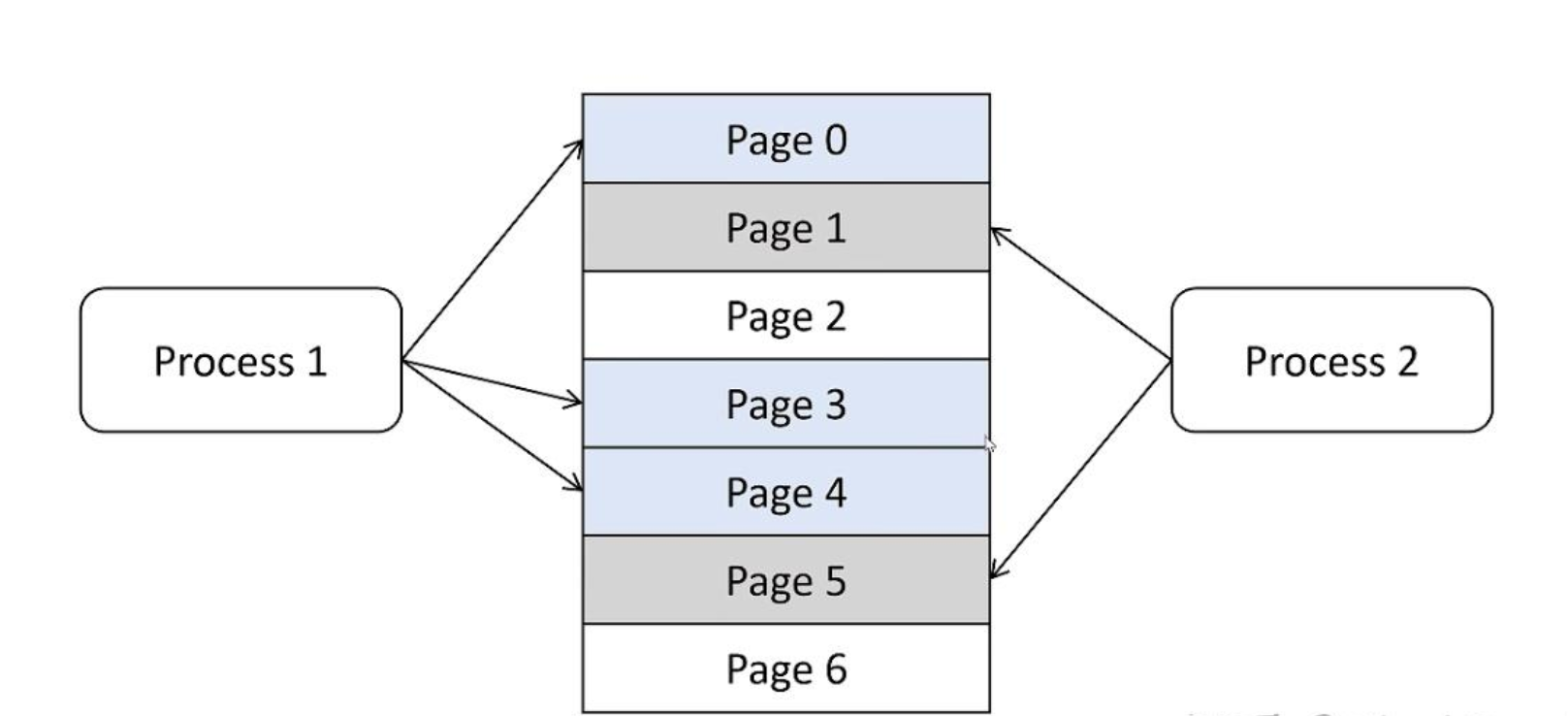
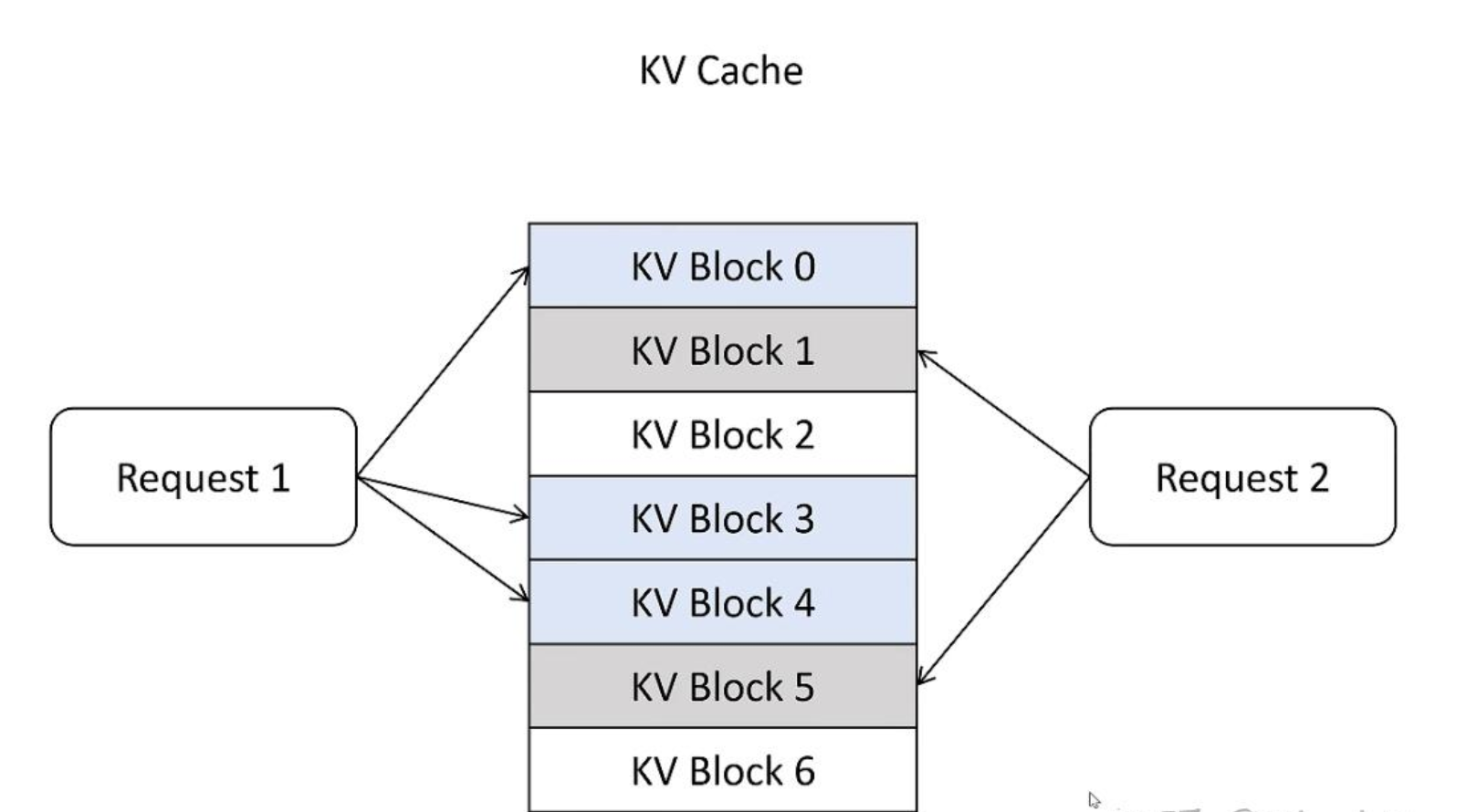
最后,我们来对比一下OS的分页机制和vLLM的PageAttention:
| 对比项 | 操作系统 | vLLM |
|---|---|---|
| 硬件基础 | 内存 | 显存 |
| 存储管理方式 | 分页内存管理 | PageAttention |
| 存储分配对象 | 进程 | 序列 |
| 存储计量单位 | Bytes | Tokens |
| 逻辑存储单元 | 虚拟内存中的Page | 逻辑KV Blocks |
| 逻辑->物理映射 | Page Table | Block Table |
| 物理存储单元 | 物理内存中的Frame | 物理KV Blocks |
一些其他的补充点:
共享KVCache:在一些场景下,比如做beam search时,可能会存在共享,此时会有操作系统里面的copy on write的机制。这里就不作为重点讲了,这个是vLLM除了PageAttention之外的另一个优化点。
Ray
Placement Group
Placement Group 可以理解为一组资源分配方案,允许用户精确控制资源的分配和任务的调度。
假设你有一个包含8GPU、16CPU的节点,现在想用一半的资源构成资源组进程任务的调度。
import ray
from ray.util.placement_group
# 创建包含8GPU、16CPU的Ray集群
ray.init(num_cpus=16, num_gpus=8)
# 创建包含4个bundle的placement group,共计使用一半的资源
pg = placement_group(bundles=[{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1}])
# 等待资源组创建完成
ray.get(pg.ready(), timeout=10)
TODO: 补充其他概念